1. 哈希函数迎来“超跑”级升级:Rapidhash速度突破70GB/s (New high-quality hash measures 71GB/s on M4)

告别拥堵,迎接闪电!新一代哈希函数rapidhash横空出世,速度与质量并驾齐驱,堪称哈希界的“超跑”。作为SMHasher权威推荐的最快哈希函数,rapidhash实力碾压前辈wyhash,无论处理短小精悍的数据还是海量信息,都能做到快如闪电,在苹果M4芯片上轻松突破70GB/s的速度上限!它不仅精通AMD64和AArch64两大平台,还兼容gcc、clang、icx和MSVC等主流编译器,简直是程序员的福音。更令人惊喜的是,rapidhash在SMHasher和SMHasher3的严苛测试中全部满分通过,防碰撞能力卓越,即使面对16B和66B的超大数据集也能表现出色。实验证明,rapidhash在处理16.1B规模的不同密钥时,碰撞概率接近完美理想值,性能稳定可靠。
原文链接:https://github.com/Nicoshev/rapidhash
论坛讨论链接:https://news.ycombinator.com/item?id=43981971
论坛的讨论围绕哈希函数的质量和性能展开。一位用户指出,对于小键值的哈希,Rapidhash是目前最先进的,没有其他更好的选择。虽然XXH3等函数在批量哈希处理上较快,但它们在质量上较弱,无法通过质量测试。
另一位用户询问XXH3未通过的质量测试细节。随后,有用户解释了哈希函数的质量衡量标准,即对于任何给定的哈希键集合,它作为随机预言机的概率。测试套件会用数万个键集和数十亿个具有不同属性的键进行测试,并将测试得出的概率分布与随机预言机进行比较。像SHA-256这样的最佳密码哈希函数非常接近随机预言机,而较弱的密码哈希函数(如MD5)则相去甚远。许多非密码哈希函数在某些测试中与随机预言机的差距很大,实际上已经失效,XXH3就是其中一个例子。
讨论还强调了哈希质量是键集合的函数。如果预先知道键集合的属性,就可以构建一个针对特定情况具有最佳质量和性能的哈希函数,即使它对于许多其他键集合来说完全失效。一个哈希函数要声称适用于“通用目的”,它需要在所有键大小和键分布中始终接近随机预言机。大多数非密码哈希函数会牺牲质量来提高延迟,而低延迟和小I-cache占用对于实际系统中基于小键的哈希性能至关重要。
2. 94行Ruby代码,打造超高效AI编程Agent! (Coding agent in 94 lines of Ruby)
![]()
还在苦恼搭建代码编辑Agent很复杂? 别担心, Thorsten Ball告诉你,用Go语言只需400行代码就能搞定!但等等,还有更酷的!一位开发者受到启发,发现用Ruby可以更简洁地实现,关键在于Ruby擅长去除冗余代码。最终,仅用94行Ruby代码就打造出一个功能完备的 coding Agent,它能读取、列出和编辑文件。
这个Agent的核心是AI聊天循环,再赋予它三个关键工具:读取文件、列出文件、编辑文件。通过RubyLLM gem,开发者轻松配置并连接到Anthropic等多种LLM。更厉害的是,通过增加运行shell命令的工具,Agent还能测试自己的代码,不断迭代优化。
原文链接:https://radanskoric.com/articles/coding-agent-in-ruby
论坛讨论链接:https://news.ycombinator.com/item?id=43984860
论坛用户围绕Ruby语言在AI时代的应用展开了讨论。多人认为Ruby简洁易懂,尤其适合处理AI生成的代码,因为其清晰的结构能有效避免潜在错误。一位用户分享了自己使用RubyLLM的经验,并提到用Ruby可以简单直接地与LLM交互,避免过度依赖LangChain等框架。另有用户贴出了自己之前关于LLM应用的博客链接,虽然内容略有过时,但仍然能启发思考。作者现身说法,表示自己仅用3小时就完成了相关代码,并鼓励大家在此基础上进行二次开发和实验。还有用户提出了通过命令行和权限控制增加额外功能的方法,例如结合API进行数据分析,将LLM系统作为前端,连接后端自定义函数,构建数据分析、建议和推荐系统。他分享了自己构建LLM聊天界面,并结合数据库访问提供学习建议的经验,并表示乐于提供相关方面的帮助。
3. 告别 Xcode!跨平台 iOS 开发神器 Xtool 问世 (XTool – Cross-platform Xcode replacement)

告别Xcode!跨平台iOS开发利器xtool横空出世!还在为Xcode的平台限制烦恼吗?现在,有了xtool,iOS应用开发将不再局限于macOS!这款开源工具让你在Linux、Windows(通过WSL)甚至macOS上都能用SwiftPM构建、签名和部署iOS应用。
xtool模拟了Xcode的核心功能,利用开放标准,让开发者摆脱平台束缚,拥抱更自由的开发体验。它不仅可以方便地将SwiftPM包转化为iOS应用,还能进行签名和安装,甚至可以通过命令行与苹果开发者服务互动。
xtool的功能强大而全面,包括项目创建、构建运行、设备管理(设备列表、应用安装卸载、应用启动)以及与苹果开发者服务交互等。更令人兴奋的是,xtool还提供了一个库,开发者可以在自己的应用中调用,实现与苹果开发者服务和iOS设备的深度集成。
原文链接:https://github.com/xtool-org/xtool
论坛讨论链接:https://news.ycombinator.com/item?id=44011515
论坛上关于一款名为 “xtool” 的 “Xcode替代品” 的讨论集中在它是否真正能摆脱对Xcode的依赖。
最初,有用户质疑该工具宣称的“Xcode-free development”,认为构建iOS应用离不开Xcode提供的库和编译器。然而,开发者解释说,xtool并非完全取代Xcode,而是构建在iOS SDK和工具链之上,而这些目前由苹果打包在Xcode中发布。即便用户不使用Xcode IDE或xcodebuild,也需要安装Xcode来获取这些工具链。
xtool的创建者进一步解释,如果仅仅是Xcode的附加层,xtool将无法支持Linux,因为Xcode无法在Linux上运行。在macOS上需要Xcode只是为了获取iOS SDK。在Linux上,用户需要提供Xcode.xip的副本,以便提取SDK。xtool不依赖Xcode的构建系统、用户界面或专有工具,甚至签名和安装也使用了其他方案:代码签名使用 MIT 许可的 zsign,安装依赖开源的 libimobiledevice 项目。
有人询问是否可以仅从Xcode包中获取SDK,就像Asahi的安装程序只从苹果服务器上下载macOS镜像的相关部分。开发者表示,由于XIP格式的限制,无法像ZIP一样随机访问,因此无法实现。尽管如此,讨论者指出,某些组件可能是可以单独下载的,但它们实际上是Xcode的一部分。最后,有用户指出这个 “跨平台 Xcode 替代品” 似乎并非完全跨平台,iOS开发者仍然需要macOS,但这一观点遭到了反驳,因为用户并不需要macos。
4. “Wow!”信号再寻觅:全球业余射电望远镜网络启动 (Wow@Home – Network of Amateur Radio Telescopes)



“Wow@Home”计划正招募全球天文爱好者,共同寻找宇宙中的“Wow!”信号!该项目灵感源于著名的“Wow!”信号,旨在通过建立一个低成本、全天候运行的小型射电望远镜网络,填补大型专业天文望远镜在持续监测瞬变宇宙事件和搜寻地外文明信号方面的空白。
这些小型望远镜成本仅约500美元,利用地球自转扫描天空,并依靠软件进行数据分析。虽然灵敏度不如大型望远镜,但其全球分布和协同观测能力使其在验证信号、排除干扰方面独具优势。该项目由“Arecibo Wow! Project”的分析方法驱动,目标是在2025年8月15日发布首个硬件推荐和软件版本,并于8月23日举办星空派对。
原文链接:https://phl.upr.edu/wow/outreach
论坛讨论链接:https://news.ycombinator.com/item?id=44011489
论坛中有用户指出该项目类似于缩小版的Argus计划,并建议可以使用SARA的“scope in a box”来降低成本。一位用户分享了自己20年前在后院搭建Argus项目的经历,后来搬到美国,却发现居住空间并不像想象中宽敞,导致设备一直闲置。他计划退休后回到英国,重新启动该项目,并对光学天体摄影也感兴趣,希望找到一个博特尔等级较低的地点,同时兼顾学校 proximity 和妻子的意见。
有人提出远程托管设备的模式,并分享了一个相关网站。分享经历的用户表示感谢,并称已将一些远程站点列入考虑范围。另一位用户表达了对该项目的兴奋之情,因为他曾经运行SETI@Home项目,并询问如何提供帮助。根据FAQ,该项目欢迎在RFI屏蔽和软件GUI开发方面有经验的人提供帮助,并欢迎技术支持、推广或合作。
5. MCP深度解析:能否终结AI工具集成的“巴别塔”困境? (MCP: An in-depth introduction)
大型语言模型(LLM)在与Sentry(监控)、GitHub(代码库)等多样化工具交互时,常陷入“M x N”定制开发的泥潭,即每新增一个工具或LLM应用,都需开发新的专用接口,导致效率低下。为破解此局,MCP(模型上下文协议)应运而生。它如AI工具领域的“USB-C”接口,致力于将复杂的连接关系简化为“M + N”模式,即每个工具和LLM应用只需实现一次MCP适配,即可互相通信,大幅降低集成成本和安全风险。
在一次生动的演示中,一个AI助手(Cline)在VS Code编辑器内,通过MCP成功串联Sentry和GitHub:它首先从Sentry获取了一个Cloudflare应用的错误堆栈,接着通过GitHub MCP创建了问题、修补了代码、提交并重新部署,整个过程在人类批准下完成。
MCP的优势在于其协议统一带来的便捷性和工具可发现性的提升。然而,这项新技术也面临延迟增加、安全管理(如令牌处理)复杂化、学习曲线较陡峭以及生态系统尚不成熟等挑战。尽管如此,MCP展现出的巨大潜力令人瞩目,未来有望在“人在环路”的监督模式下,为AI应用开发带来革命性的便捷。
原文链接:https://www.speakeasy.com/mcp/mcp-tutorial
论坛讨论链接:https://news.ycombinator.com/item?id=43972334
论坛中,一些用户对MCP(Machine Communication Protocol)的理解和文档质量表示困惑。有人认为即使阅读了MCP的介绍和示例后,仍然不清楚LLM、MCP服务器和客户端各自的角色和数据流,批评其文档是他们见过的最糟糕的技术文档,缺乏解释,业余且含糊不清。
另一些用户则认为,阅读MCP规范后,发现它本质上是客户端和一个或多个服务器之间的JSON RPC,AI代理交互并非协议设计的重点,该协议是AI无关的。工具调用工作流程包括:客户端从已知服务器请求工具列表,转发给AI代理;AI调用工具时,返回请求给MCP服务器处理;最后将结果返回给AI。甚至有人认为MCP规范非常简单,无需SDK,只需使用HTTP客户端库编写脚本即可。
还有人认为MCP规范不如一篇博客文章,指出它没有真正区分JSON-RPC+Auth之外的内容,但正因其通用性,LLM可以利用它做任何事情。有人感谢提供了MCP规范,认为这是第一次理解了具体内容。然而,也有人批评该规范质量不高,像是LLM生成的。也有用户指出MCP客户端和MCP宿主之间的概念混淆,认为这种分离毫无意义。最后,有人批评MCP是反模式的集合,认为它和Langchain一样,很快就会被遗忘,但也有人认为MCP的优势在于它允许使用像Claude Pro这样的统一费率连接任意工具。
6. Rustls服务器性能飞跃:TLS安全协议实现重大突破 (Rustls Server-Side Performance)
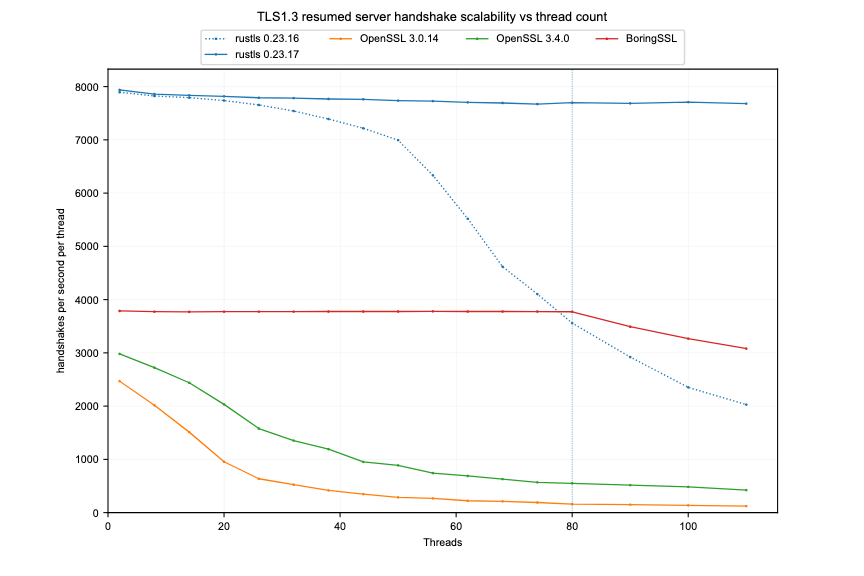
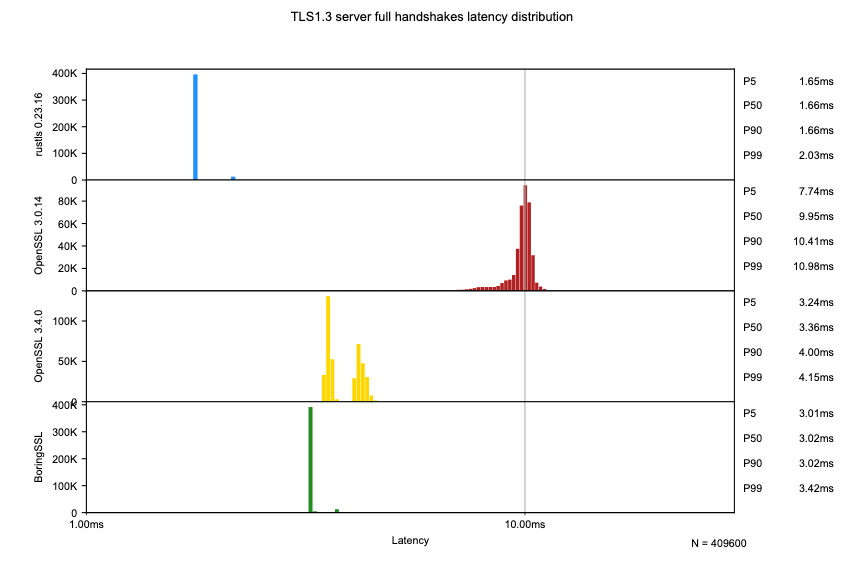
互联网安全再升级!Rustls项目近日宣布其TLS安全协议实现取得重大性能突破,特别是在高并发服务器环境下的表现令人惊喜。Rustls是一种以内存安全著称的TLS实现,旨在替代存在诸多安全漏洞的C语言编写的OpenSSL。最新测试表明,Rustls在服务器端处理大量并发连接时,能够近乎线性地扩展性能,充分利用多核处理器的优势。
本次优化主要集中在会话恢复机制上,通过将密钥轮换的互斥锁改为读写锁,并减少默认发送的ticket数量,显著降低了高并发场景下的竞争,提升了整体性能。测试结果显示,Rustls的核心TLS握手处理延迟比OpenSSL低约2倍,且在高负载下仍能保持较低的延迟。这一改进对于提升互联网服务的安全性与响应速度至关重要,预示着更安全、更高效的互联网未来。项目负责人表示,他们将继续致力于在不牺牲安全性的前提下,进一步优化Rustls的性能,为互联网用户提供更可靠的保障。
原文链接:https://www.memorysafety.org/blog/rustls-server-perf/
论坛讨论链接:https://news.ycombinator.com/item?id=43972669
论坛上关于Rust语言的讨论热烈。有人认为Rust在关键领域表现出稳定提升,虽然学习曲线陡峭,但其特性集难以复制,对其他系统语言构成挑战。另一些人则对盲目推崇用Rust重写的“RiiR教派”持保留态度,但认可在保证安全的前提下合理使用Rust,认为长期来看,通过适当的努力,Rust可以超越C++。
参与rav1d项目的人员表示,Rust在多数情况下与C语言速度相当,但在处理大型复杂代码时,Rust的优势在于其编译器强制执行的规则,能够增强代码正确性的信心,尤其是在多线程和算法复杂性方面,可以更自信地减少锁定、优化内存管理和状态处理。rav1d的性能挑战之一在于其代码主要是从C翻译而来,并非纯正的Rust风格,影响了编译器优化效果。
同时,有人指出,为新项目选择Rust与重写现有代码库是完全不同的,后者成本高昂。但也有人认为代码移植比想象中容易,并提到ChatGPT可以辅助完成初步转换,但可能引入细微错误。总之,C和C++仍然是优秀的语言,但有时Rust确实是更好的选择。
7. 日本IC卡:奇妙科技背后的速度与安全 (Japan’s IC cards are weird and wonderful)

日本的公共交通系统以高效著称,其中快速的IC卡支付体验尤其引人注目。这背后离不开索尼开发的FeliCa技术,它是一种近场通信(NFC)标准,速度高达424kbps,远超西方的MIFARE等技术。FeliCa于1988年问世,早于MIFARE,并率先在香港的八达通卡上得到广泛应用,之后被日本的Suica卡采用。
与西方不同的是,FeliCa卡采用“储值卡”模式,交易数据直接储存在卡片上,无需与服务器交互,大大提高了速度。此外,FeliCa还具备冲突避免功能,可防止同时读取多张卡。
Osaifu-Keitai是日本特有的手机支付系统,允许用户将手机模拟成IC卡。虽然所有支持NFC的手机都支持FeliCa,但要实现Osaifu-Keitai功能,还需要手机厂商获得授权并配置密钥。值得一提的是,所有型号的iPhone都支持Osaifu-Keitai。
尽管将余额存储在卡片上,但FeliCa卡的安全性极高,极难被复制或攻击。潜在的攻击点可能存在于苹果的IC卡实现或离线终端(如自动售货机)上,但风险仍然很低。有技术爱好者正计划搭建一个微型火车系统来深入研究相关技术,并探索FeliCa速度优势背后的物理原理,期待未来能实现亚毫秒级的支付体验。
原文链接:https://aruarian.dance/blog/japan-ic-cards/
论坛讨论链接:https://news.ycombinator.com/item?id=43993711
论坛的讨论围绕伦敦和东京地铁闸机的设计哲学差异展开。东京的闸机默认开放,只有当卡无效时才会关闭,这提高了通行速度。有评论者认为,这种设计体现了对乘客的信任,同时考虑到偶尔需要乘坐地铁的特殊情况。有人分享了自己未购票通过闸机的经历,并得到了工作人员的协助。
另一位评论者指出,日本闸机通常有两组门,可以根据乘客的移动方向快速关闭,且显示屏位置更靠前,方便乘客查看费用。这种高效设计与日本文化中对秩序和规则的重视密切相关。
然而,也有人反驳了“所有日本人都乘坐公共交通”的观点,指出日本有近一半的人口(15岁以上)选择驾车通勤,尤其是在城市核心区以外的地区。一位评论者认为,美国人其实比日本人更遵守规则,但对公共交通的尊重程度较低,并存在一种反绅士化的意识,认为改善公共交通可能会吸引富人,从而损害穷人的利益。
8. 家庭自动化新玩法:内核开发者体验 Home Assistant (A kernel developer plays with Home Assistant)
Home Assistant(HA)这款开源家庭自动化平台,正日益受到极客们的喜爱。它让你摆脱对云服务的依赖,将智能家居的控制权牢牢掌握在自己手中。尽管HA背后有公司Nabu Casa的支持,并提供订阅服务,但项目依旧保持开放,拥有活跃的开发者社区,贡献者超过900人!现在,HA的整体管理已移交给开放家庭基金会,未来发展稳定可期。
不过,HA的安装方式对Linux用户来说有点特别,推荐的安装方式是使用 Home Assistant 操作系统,一个定制的 Linux 发行版,在 Docker 容器中运行 HA。安装后,HA本身功能有限,需要用户通过“集成”来连接家中的各种设备,这就像安装设备驱动程序一样。许多集成来自 Home Assistant 社区商店(HACS),安装HACS需要GitHub账户。
安全性方面,HA收集大量家庭数据,并可能暴露在互联网上,存在潜在风险。该项目有安全策略,并会定期进行安全审计,但第三方集成没有经过严格审查,用户需谨慎选择。总之,Home Assistant就像25年前的Linux,虽然支持众多设备,但质量参差不齐,需要用户精心挑选。
原文链接:https://lwn.net/SubscriberLink/1017720/7155ecb9602e9ef2/
论坛讨论链接:https://news.ycombinator.com/item?id=44011381
论坛上有人分享了一篇关于Home Assistant的文章,Home Assistant的创始人Paulus表示很高兴看到用户利用Home Assistant取得的成就。他提到,Home Assistant已经捐赠给瑞士的非营利组织Open Home Foundation,完全由用户资助,没有投资者参与,致力于构建注重本地控制和隐私的智能家居。
一位用户表达了对Home Assistant的感谢,并询问是否有一次性捐赠给基金会的方式。Paulus 回应说,他们不希望依赖捐赠,目前只考虑1万美元以上的捐款,并提到DuckDuckGo和Espressif的捐款。有用户建议可以参考Blender的做法,针对特定功能或项目接受捐赠。也有人建议允许用户为Nabu Casa支付更多费用来支持项目。另有用户认为可以通过宣传活动来提高捐赠意识。
另一位用户则对智能家居的可靠性提出了质疑,认为Wi-Fi网络不稳定是主要问题,很多用户使用低质量硬件或未部署Mesh AP,导致设备容易受到丢包和高延迟的影响。他还提到,用户更换Wi-Fi SSID后,智能设备经常出现问题,最终用户可能会放弃使用智能家居设备。
9. JavaScript的“超能力”:显式资源管理强势来袭 (JavaScript’s New Superpower: Explicit Resource Management)
JavaScript迎来资源管理新纪元!一项名为”显式资源管理”的新提案,旨在帮助开发者更精准地控制诸如文件句柄和网络连接等资源的生命周期,告别内存泄漏和性能瓶颈。该提案引入了using和await using声明,它们能在资源超出作用域时自动调用清理方法,就像给资源配备了贴心的“善后管家”。
此外,还新增了DisposableStack和AsyncDisposableStack两个全局对象,它们就像资源容器,方便集中管理和释放多个资源,确保依赖关系得到妥善处理。如果资源释放过程中出现错误,SuppressedError还能捕捉并报告,避免错误信息被遗漏。
最酷的是,Chrome 134 和 V8 v13.8 已经支持这项技术啦!这意味着我们可以编写更健壮、更高效的代码,而且维护起来也更轻松。
原文链接:https://v8.dev/features/explicit-resource-management
论坛讨论链接:https://news.ycombinator.com/item?id=44012227
论坛上围绕Symbol.dispose和Symbol.asyncDispose等提案展开讨论,核心争议在于同步(sync)和异步(async)函数之间的区分是否必要。
有人认为,该提案带有“函数颜色”问题,将同步/异步的区分渗透到各个特性中,不如Java的虚拟线程方案,后者将复杂度置于JVM内部,减轻了开发者负担。但也有人反对隐藏异步,认为显式声明异步更有助于理解代码,例如网络中断等情况。
另有观点指出,目前许多语言倾向于将所有代码都写成异步,即使同步调用者也能启动一次性事件循环。Purescript在这方面处理得较好,可以针对Eff(同步效果)或Aff(异步效果)编写代码,并在调用时决定。虽然结构化并发很棒,但大家似乎主要用语法上的努力来实现服务器中的多个顶级请求处理程序。
还有人比较了多线程和单线程异步编程的难度,认为单线程异步编程比多线程更容易推理和调试,后者容易出现竞态条件、死锁等问题。Erlang的消息传递方式则使多线程更易于处理。对于异步的看法也不一致,有人认为异步语法在简单任务中表现良好,但在构建大型结构和处理错误时会变得复杂,不如显式线程处理方式。也有人反驳了异步处理错误困难的观点,认为async/await已经解决了回调地狱问题。最后,有人赞同Java采用虚拟线程的决策。
10. 代码优化之道:条件上移,循环下推 (Push Ifs Up and Fors Down)
在软件开发中,优化代码结构能显著提升性能并减少潜在错误。本文作者分享了两条实用法则:将条件判断(Ifs)上移,将循环(Fors)下推。
“上移Ifs”意味着将函数内部的条件判断尽可能移至调用方。这样做的好处是减少重复检查,简化控制流,集中复杂逻辑于单一函数中,从而更容易发现代码冗余和无效条件。例如,与其让函数内部检查先决条件,不如将此任务交给调用方,利用类型或断言来确保先决条件成立。
“下推Fors”则提倡面向数据的编程思想,强调批量处理对象。将对单个对象的操作转化为对对象批次的操作,可以分摊启动成本,灵活调整处理顺序,甚至采用向量化等技术并行处理数据。例如,基于FFT的多项式乘法,同时评估多个点的多项式比逐个评估更快。更进一步,结合使用这两条法则,将条件判断置于循环之外,避免重复评估条件,移除热循环中的分支,从而解锁向量化潜力。这种模式在微观和宏观层面均适用,亦是TigerBeetle架构的核心,通过批量处理数据来分摊控制层决策的成本。尽管性能是“下推Fors”的主要动机,但有时也能提升代码的表达能力。
原文链接:https://matklad.github.io/2023/11/15/push-ifs-up-and-fors-down.html
论坛讨论链接:https://news.ycombinator.com/item?id=44013157
论坛中,一位用户分享了他对程序流程的理解:程序状态/流程如同一棵树,条件判断用于修剪这棵树,应尽早修剪以减少工作量。他还认为条件判断是为了确定哪些工作不需要做,而循环才是“工作”。他希望函数专注于遍历程序树或执行工作。
另一位用户提出一个相关的模型:类是名词,函数是动词。但随后有用户反驳,认为函数更像是隐藏细节的地方,而类则用于暴露信息。整个程序都在执行逻辑,函数的作用在于缩小范围。有人分享了一篇Steve Yegge的文章。
还有人指出,当类可以充当动词,函数充当名词时,会让人感到困惑,经历一段过度使用后才能找到平衡。一位有25年经验的用户表示,他从未见过这种用法,认为这只是命名不规范的表现。另一位用户将函数视为管道,数据/事件输入,其他数据/事件输出。他建议尽量减少代码缩进(分支),过多的缩进可能意味着实现与问题不匹配,或者需要将代码拆分为更小的函数。也有人表示,在CS101中就学过这个概念,并一直沿用至今。最后,有人提到了阿波罗制导计算机使用VERB和NOUN的例子,并总结这些都是很好的模型。