1. AI爬虫围攻个人网站,技术宅巧用奇技击退“机器人军团” (Using lots of little tools to aggressively reject the bots)


一位技术爱好者运营的个人网站近日遭遇“机器人大军”围攻。亚马逊、Facebook、OpenAI等公司及其他来源的爬虫程序疯狂抓取数据,尤其是作者自建的Gitea代码仓库,试图下载每个公开项目的所有提交,导致服务器资源被大量消耗,日增数据达20-30GB,网站响应变慢甚至无法访问。面对突如其来的十倍流量高峰(从每秒约8次请求飙升至20多次),精通技术的作者迅速行动,利用监控工具Zabbix、日志分析工具以及Nginx和Fail2Ban等手段,识别并屏蔽了这些不请自来的爬虫。通过设置拒绝规则和自动封禁机制,作者成功阻止了滥用行为,数日内封禁IP超700个,恢复了网站稳定。这起事件凸显了当前由AI训练等需求驱动的、对互联网个人站点的侵略性数据抓取问题。作者表示,虽然乐于分享内容,但不欢迎损害其基础设施的恶意爬取行为,成功捍卫了自己的“网络小角落”。
原文链接:https://lambdacreate.com/posts/68
论坛讨论链接:https://news.ycombinator.com/item?id=44142761
论坛就网站如何应对不受欢迎的机器人流量展开了热烈讨论。有评论提出,不少恶意抓取者会模仿大型合法机器人,因此建议利用robots.txt文件设置特殊的诱饵信息(如gzip炸弹),以便识别并自动阻止这些不良行为者。然而,另一些人则质疑为何站长们对低资源消耗如此执着,认为每秒几十个请求量微不足道,相较于对抗机器人,将精力用于优化缓存提升网站性能更为有效,并将其比作过时的节俭习惯。
反对者则强调,实际的机器人流量规模可能被严重低估,且并非所有请求都对等,例如抓取大型二进制文件可能迅速耗尽带宽。同时,他们指出缓存动态内容(如Git blame)的实现非常困难。有用户分享自身经历,表示其服务器峰值流量可达每秒上千次请求,而且很多站长使用的是配置不高的旧硬件,这种高流量确实会严重影响网站和个人使用体验。另有评论补充说,虽然机器人流量常超过合法用户但不一定造成性能问题,但在云服务上若配置不当,高流量可能导致巨额费用。讨论最后有人表示,问题的根源在于机器人所有者而非机器人本身。
2. 零工经济“反向人马”复仇:算法困境下的劳工突围 (Revenge of the Chickenized Reverse-Centaurs)



零工经济下,算法正重塑劳动关系,出现“家禽化”和“反向人马”模式:平台垄断并严控“独立”工人流程和收入,AI主导并指挥人类工作。亚马逊司机、外卖员等面临算法剥削:报酬不透明、工作遭AI监控。工人正利用科技反击,如Para等App揭示隐藏报酬,“Tuyul”类App帮司机利用算法争取派单。这些创新助劳动者从被支配转为利用算法,重获主动权。这场掌握算法的斗争,是数字时代劳动权益关键。
原文链接:https://pluralistic.net/2022/04/17/revenge-of-the-chickenized-reverse-centaurs/
论坛讨论链接:https://news.ycombinator.com/item?id=44118055
论坛上的讨论围绕马歇尔·布莱恩的著作《Manna》展开。多位用户提到该书对自动化和社会变革的预见性令人不安,但对其乐观结局表示怀疑。有用户分享了布莱恩去世的消息。关于该书的链接也有更新。讨论深入探讨了自动化对劳动力市场的影响,有观点认为低技能工作可能最先被取代,但也有评论反驳“低技能”一词,指出许多此类工作需要实际技能。有用户担忧自动化可能导致技术封建主义,并讨论了普遍基本收入(UBI)作为可能的应对方案,但承认资本可能反对,预示着未来的社会契约面临挑战。
3. 毫秒级精准!高精度时钟Mk IV震撼发布,折叠设计引领创新 (Precision Clock Mk IV)

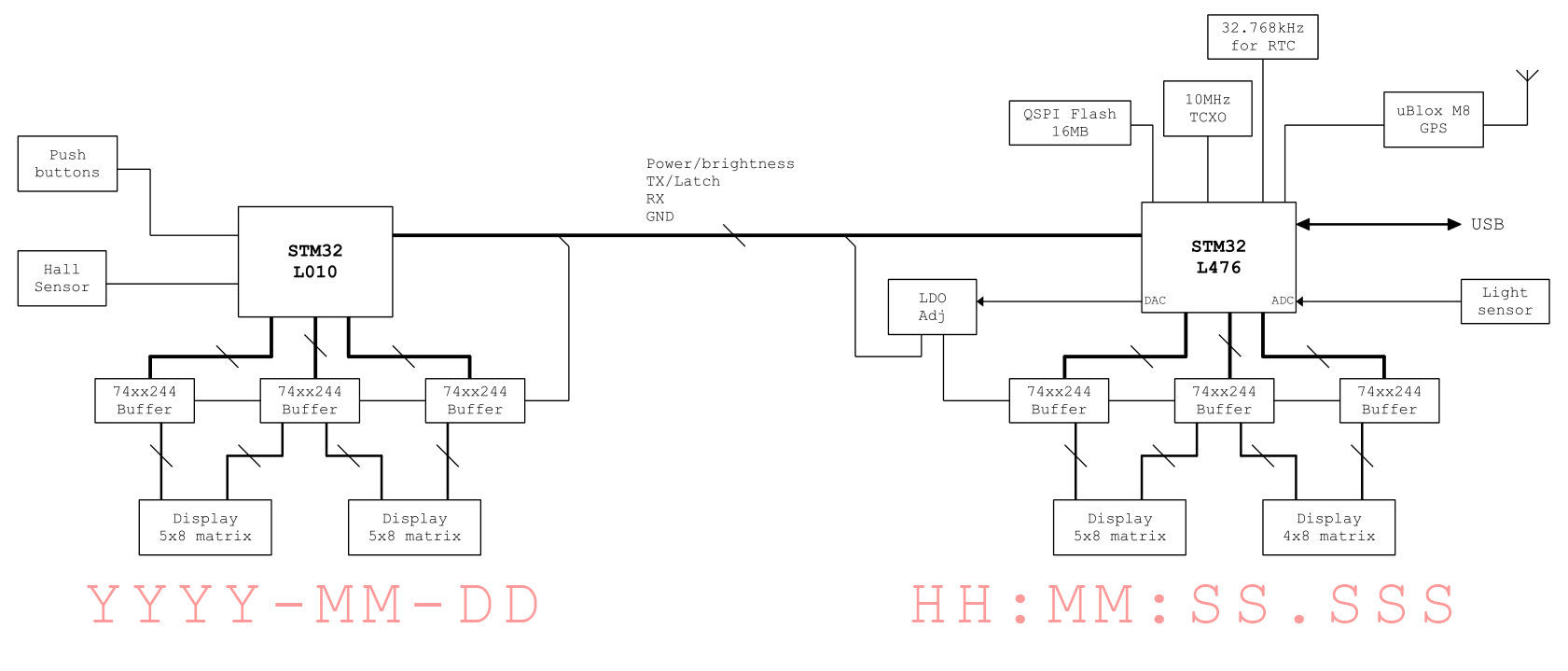
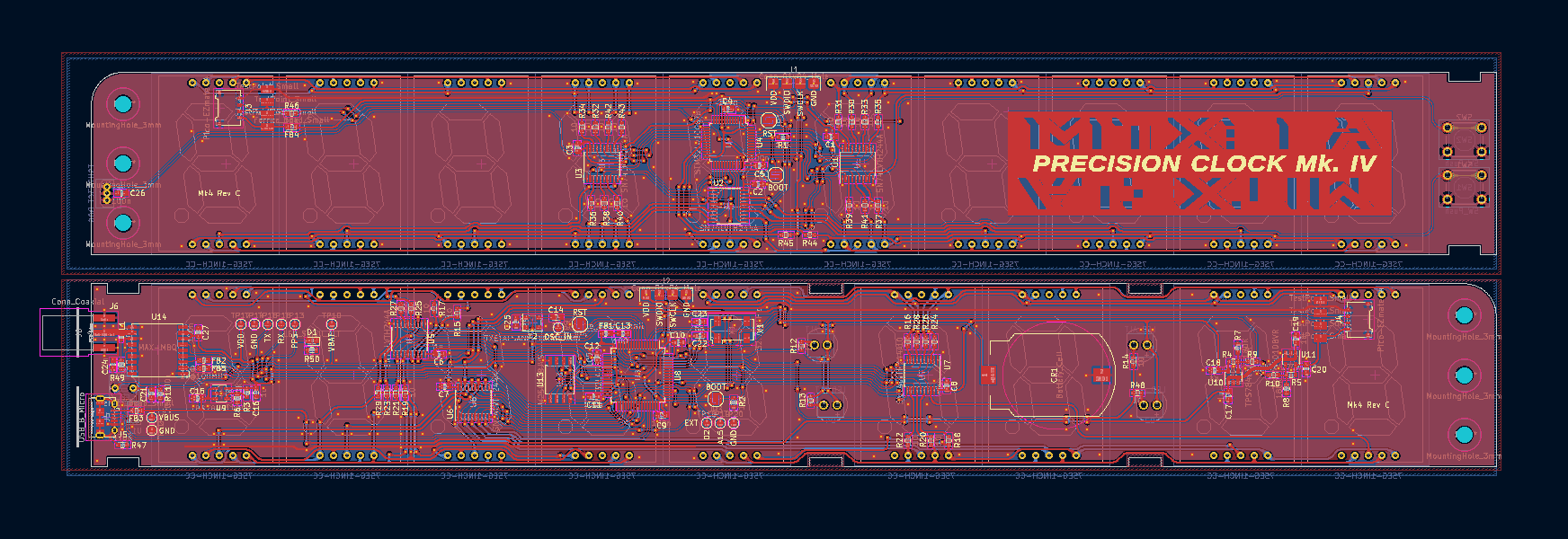
备受期待的高精度时钟 Mk IV 终于问世。开发者基于前代用户反馈,历时多年打磨,克服了疫情期间芯片短缺的挑战,倾力打造出这款集精准与创新于一体的作品。Mk IV 拥有毫秒级超高精度,即使在每秒两万帧以上的高速摄影机下也无可见闪烁。其独特亮点在于采用铰链设计,可巧妙折叠在两行或展开为宽屏显示,兼顾不同审美需求,尽管这使得内部同步(两块PCB间仅靠4根线传输数据、电源及控制信号)极具技术难度。更智能的是,它能通过 GPS 坐标自动识别并设置全球各地的时区及夏令时,内置详尽数据库,摆脱手动配置的繁琐。这款时钟融合了双处理器、DMA驱动显示、电压控制亮度调节及创新的链式固件更新等先进技术。开发者在攻克算法移植、硬件布线干扰和生产挑战(甚至遇到假芯片)后,通过高速摄影和实际旅行测试验证了其卓越性能。Mk IV 项目充满了技术探索的乐趣,最终成果已开源分享,未来甚至展望实现微秒级精度。
原文链接:https://mitxela.com/projects/precision_clock_mk_iv
论坛讨论链接:https://news.ycombinator.com/item?id=44144750
论坛讨论了一款高精度时钟显示器。用户称赞其100 kHz刷新率和为每个段配备独立驱动器的设计,实现完全无闪烁,即使高帧率相机也无法捕捉到闪烁。用户认为这是他用过最精准的时钟,尽管价格不菲,更像艺术品。讨论随后转向其他时间项目,有用户询问了发言者在GitHub上的time-pi项目。话题还延伸到通过蜂窝网络获取时间,对比了CDMA(可免费广播时间)与GSM(需订阅且精度低)的授时差异,并探讨了“时间”(time)与“计时/时序”(timing)的区别,即前者提供时间戳,后者仅指周期性间隔。
4. 韦布望远镜助力:哈勃常数再校准,宇宙膨胀之谜或将终结 (Webb telescope helps refine Hubble constant)


借助强大的詹姆斯·韦布空间望远镜,科学家们对宇宙膨胀速度(即哈勃常数)进行了新计算,有望解决困扰学界十余年的“哈勃张力”难题。过去,基于早期宇宙(宇宙微波背景)和近邻宇宙的测量结果存在显著差异,对主流的宇宙标准模型提出了挑战。芝加哥大学温迪·弗里德曼教授团队利用韦布望远镜观测多个星系的数据,大幅提升了近邻宇宙距离测量的精度。韦布望远镜分辨率是哈勃的四倍,对红外光敏感,能穿透尘埃,更准确测量标准烛光(如超新星、红巨星)的亮度。新的计算值为70.4公里/秒/百万秒差距(误差±3%),与早期宇宙的测量值(67.4公里/秒/百万秒差距,误差±0.7%)在统计上一致,表明宇宙标准模型可能依然有效。这一发现发表在《天体物理学杂志》上,未来韦布望远镜还将提供更多数据,进一步精确测量哈勃常数。科学家们正努力探寻暗物质、暗能量等未解之谜,而哈勃常数似乎不再是突破口。
原文链接:https://phys.org/news/2025-05-webb-telescope-refines-hubble-constant.html
论坛讨论链接:https://news.ycombinator.com/item?id=44114309
论坛上的讨论聚焦于宇宙学中“哈勃张力”这一未解难题。一位非专业人士提出,宇宙距离阶梯可能是误差累积导致结论偏差的最薄弱环节,如对超新星亮度恒定的假设以及尘埃影响等,认为提高距离测量精度或许能解决张力。
其他参与者指出,尽管距离测量的误差范围几十年来已持续缩小,但这种精度提升反而使得哈勃张力更加突出。这令一些人感到沮丧,认为表明现有宇宙理论可能不完整,即使有新的望远镜(如韦伯)提供更多数据,张力依然存在。有人认为这种持续性差异或许指向系统性误差。
然而,有专业人士反驳说,宇宙距离阶梯中的各种标准烛光并非独立假设,它们相互校准,科学家也花费大量精力研究如何补偿尘埃等影响。他们强调,当测量结果出现不一致时,关键在于改进测量工具本身,而不是随意调整现有工具以消除差异,否则会阻碍科学进步。
讨论中还引用了一项结合哈勃和韦伯望远镜数据的最新计算结果(70.4 ± 3 千米/秒/百万秒差距),这一数值更接近通过距离阶梯测量的结果,再次印证了哈勃张力的存在。整个讨论反映了科学界在精确测量宇宙膨胀速率方面所面临的挑战和持续探索。
5. Redis 分叉 Valkey 一周年:性能超越,重塑缓存未来 (Valkey Turns One: Community fork of Redis)


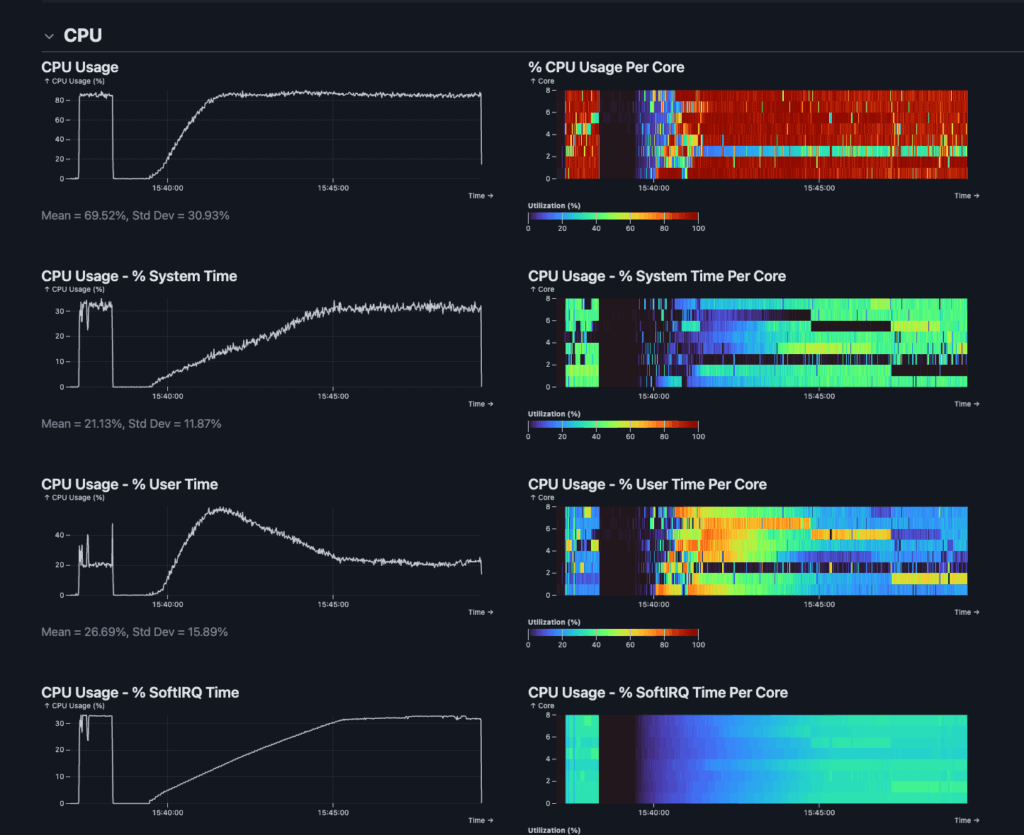
一年前,Redis协议变动引发争议,社区催生了分支项目Valkey。时隔一年,Valkey不仅存活,更蓬勃发展,并在最新基准测试中性能领先。在8核CPU实测中,Valkey 8.1写入逼近100万次/秒(99.98万),P99延迟0.8毫秒;Redis 8.0最高72.94万次/秒,P99延迟0.99毫秒。Valkey在写入(高37%)和读取(高16%)吞吐量及延迟上全面占优,凸显其对I/O线程和CPU优化的成效。虽然Redis 8.0也已重新开源,原作者回归,但Valkey展现了开源社区强大的适应性和创新力,正在加速定义高性能缓存的未来。
原文链接:https://www.gomomento.com/blog/valkey-turns-one-how-the-community-fork-left-redis-in-the-dust/
论坛讨论链接:https://news.ycombinator.com/item?id=44140379
6. 物联网福音:Erlang虚拟机AtomVM登陆微控制器,赋能低成本设备 (AtomVM, the Erlang virtual machine for IoT devices)
![]()
科技圈传来一个激动人心的消息:一个名为AtomVM的轻量级项目正在崛起。它巧妙地将通常用于运行Erlang和Elixir等强大语言的BEAM虚拟机“瘦身”并优化,使其能够运行在微小的、价格低廉的微控制器上。这意味着,开发者现在可以使用支持现代Actor并发模型的函数式编程语言(如Erlang/Elixir)来编写物联网(IoT)应用,这将极大地简化开发流程,提高代码的可读性和可靠性。
AtomVM不仅实现了进程生成、监控、消息传递、抢占式调度和高效垃圾回收等BEAM的核心功能,还能直接与微控制器的硬件外设(如GPIO、I2C、SPI、UART)交互,并在支持的设备(如乐鑫ESP32)上提供Wi-Fi网络支持。最令人兴奋的是,这些强大的功能可以在成本低至2美元的设备上实现!AtomVM的出现,为在低成本硬件上构建复杂、稳定、易于维护的IoT解决方案开辟了新的道路,无疑为科技爱好者带来了探索和创造的无限可能。
论坛讨论链接:https://news.ycombinator.com/item?id=44115897
关于AtomVM在论坛的讨论热烈。有用户认为AtomVM非常适合微控制器(MCU)原型开发,比Nerves更轻量,Nerves则用于配置更高的设备。近期一项名为Popcorn的项目引人注目,它利用AtomVM在浏览器中运行BEAM VM代码。讨论指出,近期出现了许多微型虚拟机工具,AtomVM作为WASM目标正受到Elixir社区更多关注。除了Nerves,还有类似项目GRiSP,定位介于Nerves和AtomVM之间。尽管有前Erlang工程师质疑其在IoT设备上的实际用例,但也有人强调Erlang的Actor模型灵活通用,适用于小型设备。总体来看,这些项目旨在为弹性嵌入式系统带来Erlang/Elixir能力,各有侧重,且开发者社区之间保持交流。
7. Linear同步引擎逆向解析:揭秘协同编辑的革新之道 (Reverse engineering of Linear’s sync engine)



最近,一位专注于协同软件的工程师通过逆向分析知名项目管理工具Linear的前端代码,深入探究了其备受好评的同步引擎(LSE)。Linear的联合创始人兼CTO Tuomas Artman曾高度赞扬该引擎,称其为“最佳文档”。与传统采用OT(操作转换)或CRDTs(无冲突复制数据类型)的协同编辑技术不同,LSE采取了一种以中心化服务器为真相源(SSOT)的独特方案。它通过一个全局递增的lastSyncId来确保操作的总序性。核心同步流程包括:客户端将操作封装为事务发送至服务器;服务器处理后,将增量变化以delta packets广播给所有客户端;客户端接收并应用这些delta packets来更新本地内存模型及IndexedDB缓存。值得注意的是,客户端不会直接将用户输入写入本地数据库,而是在收到服务器确认的delta packets后才进行。这种设计巧妙地实现了实时协作、强大的离线支持及高效的按需加载(如部分数据的水合)。文章详细揭示了其模型定义、启动加载、事务处理、增量同步及冲突解决(遵循“最后写入者获胜”原则)机制。对喜爱科技和协同软件的读者来说,这是一次了解先进同步技术内部运作的难得机会。
原文链接:https://github.com/wzhudev/reverse-linear-sync-engine
论坛讨论链接:https://news.ycombinator.com/item?id=44123131
论坛上,有用户对Evan Hu通过逆向工程Linear的同步引擎并写出比官方更完整、准确的文档表示印象深刻。
另一位开发者分享了他作为独立开发者,使用Rust、Postgres和Vue构建应用时面临的同步难题,目前方案简陋,询问更成熟的同步引擎构建建议。
对此,论坛用户提供了多种技术方向和具体方案。有人澄清Yjs是CRDT(冲突消解复制数据类型),而非同步引擎本身,但对处理并发有用。有人建议从简单的数据库更新日志表开始,但开发者指出其后续历史记录和当前状态处理复杂性。其他建议包括考虑Electric SQL、PowerSync等现有同步产品,以及用于本地优先应用的TinyBase、Livestore等前端存储层。还有人分享了结合Loro(CRDT)和Iroh(数据传输)的实践,并推荐了关于实现同步引擎的专业文章资源。
讨论中也有用户介绍了Linear自身的同步架构,依赖内存对象图和IndexedDB实现即时、支持离线优先的更新体验。整体来看,大家探讨了构建同步引擎的挑战、CRDT的作用,并分享了多种商业产品及开源技术作为解决方案或参考。
8. 梯度“伪区间”:三维渲染迎来效率革命 (Gradients Are the New Intervals)

高效渲染复杂三维模型是计算机图形学领域的关键挑战。文章开头幽默地将图形学研究者比作喜鹊,既容易被“闪光点”吸引,也善于“偷”好点子。背景提到利用符号距离场 (SDFs) 和分层光栅化技术,结合区间算术来加速渲染,通过跳过空闲或实体区域并简化数学表达式,显著提升效率。但区间算术存在保守性高、处理复杂变换不够灵活的问题。
IRIT和Adobe Research的最新研究受此启发,提出了一种基于SDFs“Lipschitz性质”(即梯度幅度有界)的高效分层剪枝方法。该方法的核心在于,对于符合Lipschitz性质的SDF,不再依赖复杂的区间算术,而是在区域内进行单点采样,并利用Lipschitz性质估算出距离范围的“伪区间”。利用这个“伪区间”,他们可以沿用传统的分层优化策略,例如剪枝和简化数学表达式,大幅减少计算量,实现复杂模型的高效交互式渲染。
这项新方法计算量更小,且更擅长处理复杂模型变换带来的挑战。即使对于不严格符合Lipschitz性质的SDF,他们也探索了通过梯度归一化处理后应用此方法的可行性。实际测试显示,对于理想情况,新方法因计算更简洁而表现出色。在某些复杂的非理想模型(例如包含7668个运算的挑战模型)上,经过优化的新方法与传统区间算术方法的性能表现相当,且都能将表达式从几千个大幅简化到一百多个。这项研究为高效渲染提供了一条新的技术路线,为三维图形领域带来了新的优化可能性。
原文链接:https://www.mattkeeter.com/blog/2025-05-14-gradients/
论坛讨论链接:https://news.ycombinator.com/item?id=44142266
论坛讨论了泰勒模型和区间算术等数学方法。有评论指出,泰勒模型是区间算术创始人Moore思想的延伸,其发展源于物理领域的求解需求,并在实践中有效,尽管对其区间包含精度(如超二次方精度)的说法可能存在争议,有其他技术也实现了超越二次方限制。讨论者还提及了这些方法在几何计算和图形学中的应用,如区间射线步进以及在神经网络隐式表面上的应用。此外,也有评论从数学角度分析了相关方法的局限性,如函数归一化过程的Lipschitz性质问题,并区分了符号距离函数与一般隐式曲面在梯度上的差异。讨论涵盖了技术的历史渊源、实际应用及理论细节。
9. 警惕“速算”陷阱:浮点运算优化需谨慎 (Beware of Fast-Math)
许多编译器提供“fast-math”选项,旨在提升浮点运算速度,听起来很棒。然而,它通过放松严格的IEEE 754浮点标准来实现加速,这意味着用速度换取精度和行为可预测性,可能带来意想不到的后果。例如,“ffinite-math-only”可能悄悄移除NaN检查;“fassociative-math”会重排运算顺序,影响精度甚至破坏依赖顺序的算法(如Kahan求和);更隐蔽的是,“flush to zero”选项,可能通过共享库改变线程浮点环境,影响完全不相关的代码,导致难以排查的错误。虽然在对精度要求不极致的领域(如音频、图形)有应用,但通常建议谨慎使用。开发者需通过严谨测试确认代码在特定优化下仍正确,或考虑其他并行优化方法。文章呼吁编译器提供更细粒度的控制,并改进文档,让“快”不再伴随“险”。
原文链接:https://simonbyrne.github.io/notes/fastmath/
论坛讨论链接:https://news.ycombinator.com/item?id=44142472
论坛上有讨论介绍了 Rust 语言一个正在开发的新 API,用于“代数运算”。该 API 旨在允许编译器在局部范围内,基于实数代数属性对浮点运算序列进行安全优化,区别于全局且可能不安全的 -ffast-math 编译器标志。有评论指出,-ffast-math 本身包含多项独立旗标,新 API 的主要优势在于其优化的局部性控制。另有评论建议,更实用的功能或许是语言层面协助暴露和处理浮点数的舍入误差,而非仅仅隐藏其复杂性。讨论还澄清,该 API 目前不会修改低级浮点控制寄存器旗标(如 x86 的 FTZ/DAZ),其作用是设置 LLVM 优化旗标。此外,关于“代数运算”这一命名是否最贴切也引发了简短讨论,因浮点运算虽具代数结构但不遵循所有实数代数律。
10. Mary Meeker’s first Trends report since 2019, focused on AI

原文链接:https://www.bondcap.com/reports/tai
论坛讨论链接:https://news.ycombinator.com/item?id=44139403
论坛上,一篇关于ChatGPT达到3650亿次年度搜索量所需时间比谷歌快5.5倍的报告引发了讨论。一些参与者质疑这一比较的相关性与公平性,认为将谷歌成立早期(互联网尚未普及)与如今(拥有数十亿联网设备)的环境进行对比,忽视了巨大的时代差异,可能产生误导,更像是为了吸引点击。
然而,另一些参与者则辩护称,尽管初看有失偏颇,但这种比较对于理解当前技术产品的惊人扩展速度及投资者进行预测具有重要价值。他们认为,比较的重点不在于公司本身,而是衡量在当今这个连接更紧密、基础设施更成熟的时代,产品的扩展速度能比过去快多少。具体量化的数据(如5.5倍)虽然不一定完全精确,但为常识提供了具体的证据支持,帮助人们校准对现代产品增长潜力的预期。讨论围绕比较的有效性及其在揭示不同时代扩张环境差异方面的作用展开。