1. Rust深度实现Datalog:构建高性能逻辑引擎 (Datalog in Rust)

该网页截图展示了一篇深度技术博客文章,标题为“Datalog in Rust”,核心内容围绕在Rust编程语言中实现Datalog逻辑编程范式。文章深入探讨了Datalog——一种声明性逻辑编程语言,常用于知识表示、数据查询和推理。作者在文中详细阐述了如何在Rust的强类型系统和内存安全特性下构建Datalog解释器或编译器,旨在结合Rust的高性能与Datalog的强大查询能力。内容可能涵盖Datalog规则的解析、事实的存储、查询优化以及递归评估机制等核心技术环节。文中预计包含丰富的代码示例,以直观展示Datalog规则如何被Rust代码处理和执行,可能涉及自定义数据结构、模式匹配、并发处理以及性能基准测试等Rust特有实践。文章或许还会探讨在实际开发中集成Datalog的挑战与解决方案。此类实现对于构建高性能、安全可靠的推理引擎、配置系统或领域特定语言(DSL)具有重要意义,尤其是在需要复杂数据关系查询和业务规则验证的场景。整体而言,该文章为Rust开发者提供了一个关于Datalog实现的技术指南,不仅展示了理论知识,也提供了实践层面的指导,对于探索逻辑编程与系统编程结合的开发者具有较高参考价值。
原文链接:https://github.com/frankmcsherry/blog/blob/master/posts/2025-06-03.md
论坛讨论链接:https://news.ycombinator.com/item?id=44281727
社区近期围绕Datalog展开了热烈讨论。一位用户分享了使用Differential Datalog和Rust开发实时策略游戏的经验,旨在探索新想法。对此,有评论者建议结合Salsa库进行创新。另有开发者提到,Differential Datalog已不再积极维护,并分享了将Mangle Datalog移植到Rust的进展,指出其Rust实现通过内存映射处理任意大小数据,但进度受限于优先级和“第二系统综合症”。他进一步比较了不同Datalog Rust实现(如ascent、crepe)的优缺点,指出基于宏的方法不适用于运行时查询。
讨论中,一位评论者赞扬了原帖的技术博客文章,认为其技术深度与引人入胜的叙述兼具,将优化过程描绘成侦探故事。关于Datalog的未来,有爱好者观察到近期Datalog相关会议规模缩小,认为其复兴势头似乎有所减弱,但也有人对此持不同意见。尽管如此,Datalog在数据质量管道中的应用仍被认可,认为它在识别数据问题方面比SQL更具优势,查询可读性高。评论者们分享各自项目,显示Datalog仍拥有一批核心支持者。
2. Lisp的艺术:代码、创作与科技的预见 (The Art of Lisp and Writing (2003))
编程,尤其是使用Lisp这样的语言,远不止是例行工程,它更是一种充满美感的艺术创作。如同写作般,编程是程序员与执行介质有机互动的过程,是自我表达与艺术的结合。文章指出,艺术、工程与科学并非泾渭分明的领域,而是探索真理的连续体。艺术家在创作中不断积累知识,将内在的想象与外部物质世界相结合,绘制出人类认知的可能性蓝图,甚至拓展我们对世界的理解极限。
这种艺术的预见性,常常成为科技进步的灵感源泉。例如,16世纪《浮士德》故事中,主人公乘坐飞龙马车遨游太阳的奇想,如今已通过飞行器变为现实,正如当年帆船的普及一般寻常。手机与《星际迷航》中通讯器的惊人相似,也并非巧合。正是艺术家们那些充满奇思妙想的“白日梦”,激励着科学家和工程师们孜孜不倦地探索,将想象变为触手可及的现实。艺术与科技的交织,让我们对未来充满无限期待,共同开启一个又一个令人兴奋的精彩篇章。
原文链接:https://www.dreamsongs.com/ArtOfLisp.html
论坛讨论链接:https://news.ycombinator.com/item?id=44281016
一位社区用户分享了他对编程认知的转变:过去他认为Python优雅,编程如魔法般充满乐趣。然而,随着年龄增长和主要使用Go语言,他发现编程不再那么深刻,反而更享受户外活动。他认为大型语言模型(LLM)已将曾被严格把控的编程技能商品化,并乐见AI工具简化了许多编程环节,使开发者能专注于结果而非过程。他现在更推崇那些向后兼容、功能单一、不依赖外部工具、运行快速且语法简洁的语言,并因此对Python的类型系统和依赖管理感到不满。
另一位用户对此观点提出质疑,不认为LLM导致了编程的商品化,也否认编程曾被“守门人”严格限制,指出过去二十年系统、开源代码和语言都呈爆炸式增长。第三位用户则进一步阐述,认为“人人学编程”的观念是2015年至2024年间行业灌输的。他声称企业在裁员后通过AI“窃取”开源代码,反过来指责原作者“守门”,这实为一种自私的宣传,编程从未像法律或医学那样存在真正的“守门”。最后一位用户补充道,Lisp语言(如CL、Scheme)的独特魅力在于其就业市场不佳,反而因此保留了更为“硬核”的社区和生态系统。
3. 星链Mini硬核改造:告别WiFi,直连以太网 (How to modify Starlink Mini to run without the built-in WiFi router)
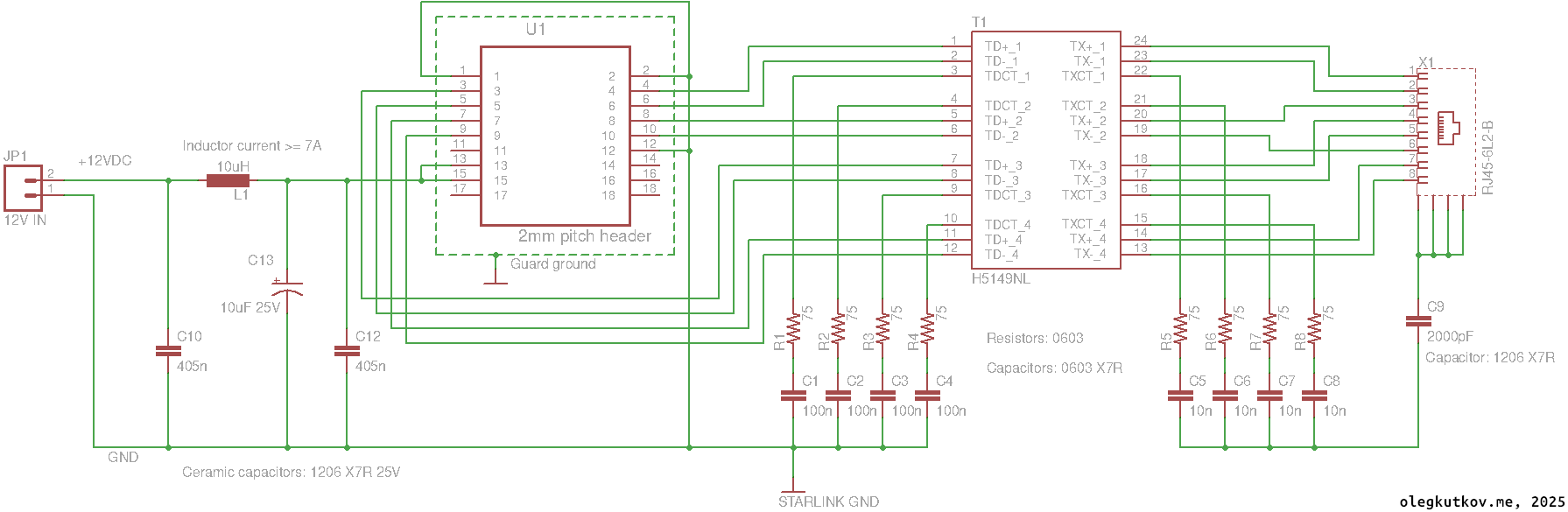
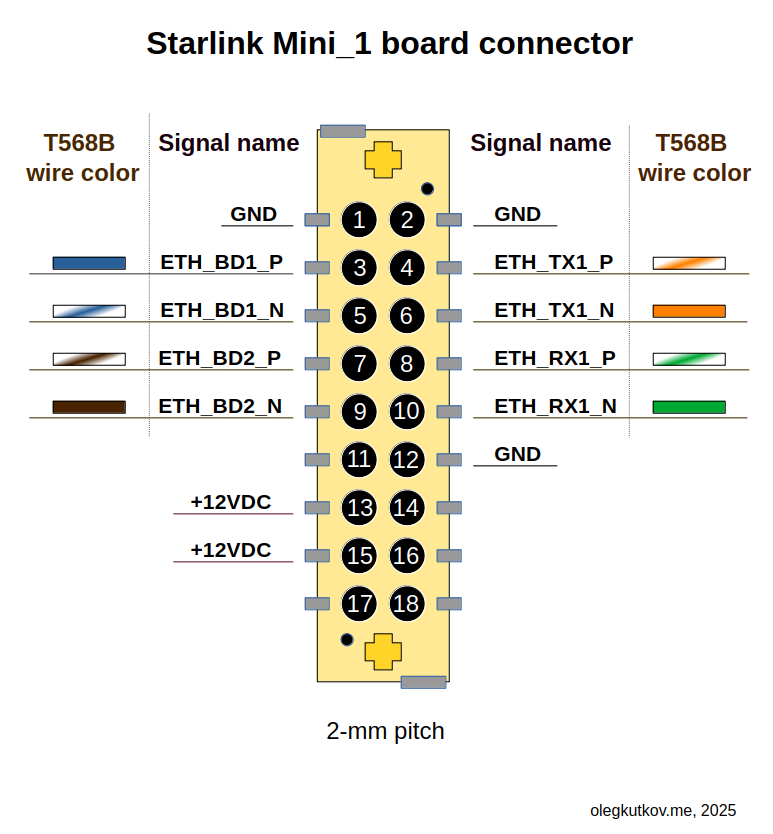

星链Mini终端以其小巧集成设计,内置Wi-Fi路由器,深受用户喜爱。然而,对于追求极致定制、嵌入式或电源敏感环境的科技爱好者,直接以太网连接能带来更大灵活性。近期,一项针对星链Mini 1代终端的巧妙改造方案浮出水面:用户可安全移除内部Wi-Fi路由器板,实现纯以太网操作。
这项改造虽需耐心与精细操作,核心在于释放设备潜能,让星链Mini更好地融入各类专业或个人定制网络。值得注意的是,此方案仅适用于Mini 1代。操作中务必避免移除主板上的金属板,它兼具散热与电磁屏蔽双重作用。移除可能导致处理器过热、性能下降,甚至引发电磁干扰。鉴于星链Mini的PCB本身就产生显著电磁辐射,且SpaceX在合规性方面曾面临挑战,保持屏蔽至关重要。
改造后的星链Mini通过12VDC电源供电,正常运行电流约3A,峰值可达5A。其主板与路由器间采用1Gbps以太网连接。移除路由器后,用户可按需配置外部网络设备,为星链Mini的部署开启更多可能性。
论坛讨论链接:https://news.ycombinator.com/item?id=44282017
社区的讨论主要围绕Starlink的“禁用代码”展开。最初有用户对卫星终端是否直接执行这些地理或速度限制代码感到困惑,怀疑其是否暗示绕过可能,并认为执行应在网络层面。
对此,有评论者澄清,这些代码实为发送给终端的通知信息(如“账户禁用”),仅为告知用户服务受限原因,而非由终端决定执行;实际限制和执行权力仍归Starlink网络。
另有用户质疑,若存在绕过方法,不太可能被公开。他们推测Starlink执行严格度不一,并指出其在俄罗斯(尤其克里米亚、顿巴斯和卢甘斯克被占区及部分边境)可被使用,这本不应发生,可能因地理围栏不精确或边境争议导致划定困难。
讨论还涉及Starlink的技术细节,有用户对内部使用调制板对板以太网而非RGMII接口感到好奇。对此,有解释称以太网更便于原型开发和测试,尤其利于不同团队协作,从而简化集成、加快发布。同时,也有人指出RGMII是以太网模块化设计的一部分,常用于外包物理层。
4. 激光雷达看穿千年迷雾,密歇根古代农田重见天日 (Fields where Native Americans farmed a thousand years ago discovered in Michigan)

借助无人机激光雷达(Lidar)技术,考古学家在密歇根州的森林深处,发现了一处有千年历史的美洲原住民农业遗址。该遗址由梅诺米尼部落的祖先建造,其广阔的田垄系统可能是美国东部现存最大的古代农田。
放射性碳定年法显示,这些土垄约建于1000年前,曾用于种植玉米、豆类等作物。研究还揭示了古人用木炭和湿地土壤改良土质的精耕智慧。这一发现颠覆了学界认知,因为在当时寒冷的“小冰期”气候下,于如此北方的地区进行大规模农业生产极为不易,其背后的动因仍是未解之谜。本次科学家与部落合作的探索,生动展现了现代科技如何揭开被时间与森林掩盖的古老历史。
论坛讨论链接:https://news.ycombinator.com/item?id=44257422
社区讨论围绕一项研究展开,该研究发现古代美洲原住民农民可能将木炭和破碎陶器用于田地堆肥。一位评论者首先指出,由公共资助的研究论文应向公众开放,否则令人不耻。
随后,讨论聚焦于研究发现。有用户将原住民的这种堆肥方式与“黑土”(Terra Preta)联系起来,认为这种做法在美洲大陆广泛存在,体现了原住民卓越的植物知识,并希望发掘更多此类失落的知识。
对于破碎陶器如何能用作堆肥的疑问,多位讨论者提供了详细解释。他们指出,当时的陶器通常是低温烧制、未经玻璃化且未上釉的,因此具有多孔性,能吸收水分并随着时间分解。有业余陶艺师分享经验,现代园艺中使用的蛭石、赤陶花盆以及埋入式渗水陶罐(Ollas)都利用了陶器的多孔吸水特性。还有人提到盆景和水培中使用的低温烧制粘土,也具有良好的保水性。
最后,讨论延伸至更原始的工艺。一位用户思考在野外从零开始制作陶器的可能性,认为少数熟练的工匠就能再现文明的基础。另一位用户则引用YouTube频道“原始技术”的例子,证实了这种可行性。
5. 树莓派:虚拟显示器EDID的“神来之笔” (Modifying an HDMI dummy plug’s EDID using a Raspberry Pi)


科技世界总充满奇思妙想!道格·布朗最近分享了一个巧妙的解决方案:他成功将廉价4K HDMI虚拟显示器插头(dummy plug)“降级”为1080p设备。这些小巧的虚拟插头内置EDID(扩展显示识别数据)芯片,能让无头服务器误以为有显示器连接。当默认4K分辨率不适用时,如何调整成了一大难题。
布朗的创新在于,他利用树莓派(Raspberry Pi)改写虚拟插头的EDID数据。目标是将虚拟插头信息替换为1080p HDMI采集设备的EDID副本,让电脑接收所需分辨率信息。令人兴奋的是,树莓派(特别是Pi Zero)的HDMI端口自带I2C控制器,这正是读写EDID EEPROM芯片的关键。
不同型号树莓派对应不同I2C总线(如Pi 0-3为/dev/i2c-2,Pi 4为/dev/i2c-20/21,Pi 5为/dev/i2c-11/12)。此操作虽精妙,但需极其谨慎,务必确保仅对虚拟插头而非真实显示器进行,以防意外损坏。
原文链接:https://www.downtowndougbrown.com/2025/06/modifying-an-hdmi-dummy-plugs-edid-using-a-raspberry-pi/
论坛讨论链接:https://news.ycombinator.com/item?id=44282998
社区中关于HDMI虚拟插头的讨论涉及其功能、局限性及相关HDCP(高带宽数字内容保护)问题。
有评论指出,廉价虚拟插头通常只配备256字节EEPROM,不足以模拟高分辨率高刷新率(如4K240Hz)显示器,但对1080p60Hz则足够。同时,部分插头有写保护,需要改造才能写入数据,写保护状态取决于具体芯片。
讨论的重点很快转向HDCP。一位用户提到,这类虚拟插头不支持HDCP,无法用于测试需要HDCP才能全分辨率播放的视频流应用,并寻求一种支持HDCP协商的类似解决方案。他提到HDMI多画面分配器可能具备此功能。针对HDCP问题,另一位用户推荐了一款HDMI分配器,它能预设或学习EDID信息,并模拟显示器连接,据信能在电脑与分配器之间协商HDCP,再将信号输出。还有评论提及,全球速卖通及Decimator等品牌可能销售能终止HDCP并转发HDMI信号的设备。
多位讨论者对HDCP/DRM表达了强烈不满。有人认为,在这些绕过设备存在的情况下,显示器与电脑间的信号仍需加密是“疯狂”的。更有人指出,DRM带来的只有负面影响,如4K电视因HDCP版本不兼容而无法播放内容,或因软件/电气问题导致连接失败。他们普遍认为视频DRM从未真正发挥作用,反而使所有人的体验变差。最后,有用户建议,对于显示器而言,DisplayPort是更好的选择,因为它不涉及HDCP。
6. “视界诅咒”:揭示阻碍通用AI前行的强化学习瓶颈 (Q-learning is not yet scalable)

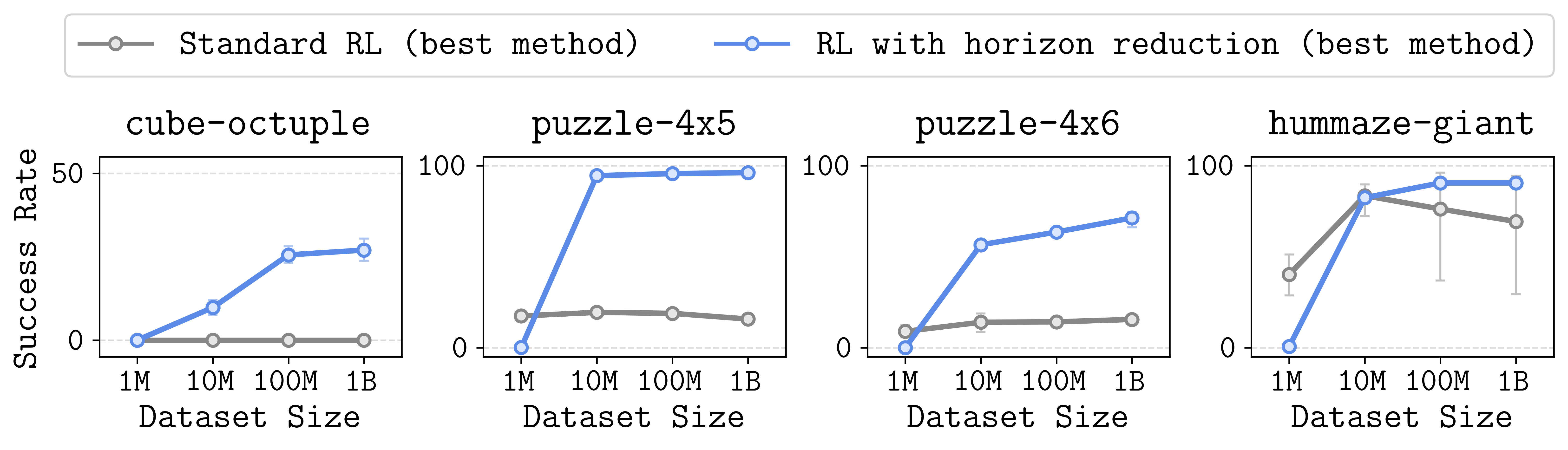
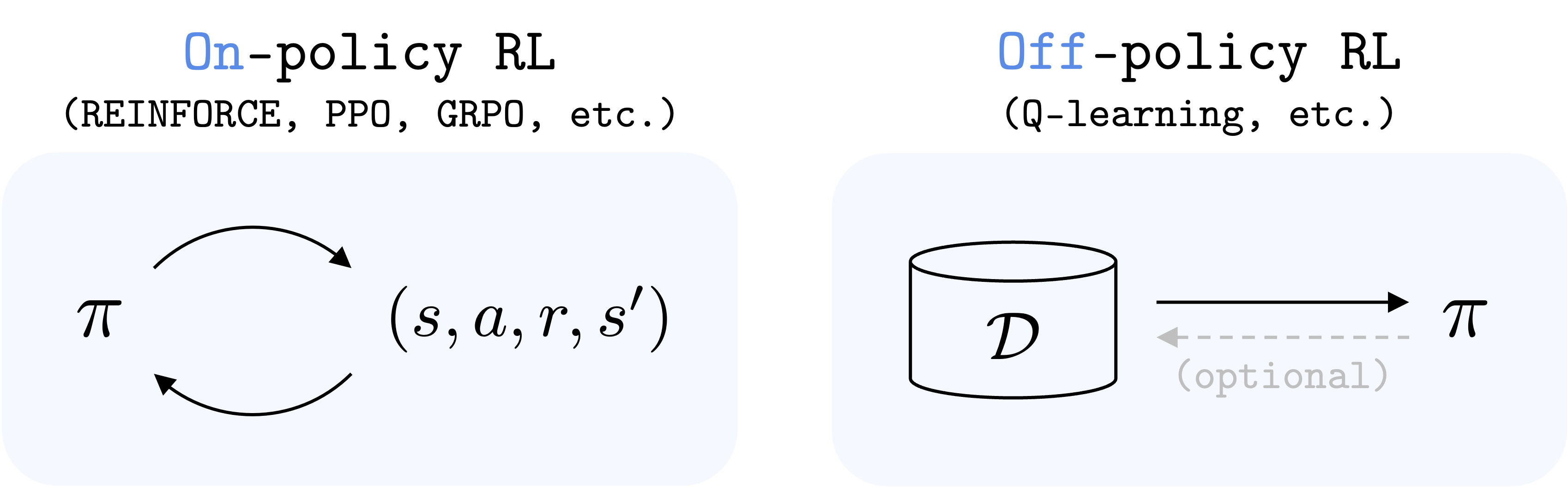
虽然语言模型等AI技术已展现出惊人的扩展性,但被视为通向通用智能体关键的强化学习(RL)却面临一个核心瓶颈。加州大学伯克利分校的研究者指出,问题出在应用最广的离线强化学习算法Q-learning上。
该算法在处理需要连续多步决策的“长视界”任务时,其预测目标的微小偏差会不断累积,最终如滚雪球般被放大,导致学习失败,这便是“视界诅咒”。在一项机器人控制实验中,即使将数据量提升1000倍,标准算法依旧束手无策,唯有通过“缩短视界”等技巧抑制偏差累积才能提升性能。因此,寻找一种能从根本上解决偏差问题、真正可扩展的离线强化学习算法,已成为当下机器学习领域最重要的挑战之一,它的突破将为机器人与通用AI解锁巨大潜力。
原文链接:https://seohong.me/blog/q-learning-is-not-yet-scalable/
论坛讨论链接:https://news.ycombinator.com/item?id=44279850
社区就Q-learning的局限性展开了讨论。一位评论者指出,其主要可扩展性问题在于,随着时间步(horizon)增加,可能的状态数量呈指数级增长,导致训练所需的指数级数据量;而on-policy学习通过聚焦相关状态规避此问题。
另一位讨论者则认为,文章对Q-learning中Max操作符导致的“过度近似偏差”分析准确,这会在时间步中放大噪声,尤其在网络访问次数较少的状态中。但他反驳了指数级状态增长的观点,认为若状态存在可学习模式,深度学习可处理,关键在于正确的训练目标。该用户还提出,MuZero等基于模型的强化学习系统可能是解决方案,因其能通过重新分析轨迹提高效率,并利用蒙特卡洛树搜索(MCTS)处理多步展开。
有用户提及,某些“均匀”或“遍历性”任务,即使样本质量不高也可能奏效,并有评论者澄清Q-learning适用于状态增长率远低于指数级的情况。一位讨论者将此与蒙特卡洛积分的常规网格和重要性采样进行类比。最后,一位用户精辟总结道,价值型强化学习面临“追逐移动目标”的挑战,因为方程两侧都包含近似值,缺乏一个固定的真实基准。尽管存在这些挑战,该用户仍对强化学习的未来表示乐观。
7. 给鸡戴眼镜?这项百年发明太“离谱”了! (Chicken Eyeglasses)
![]()
20世纪初,一项旨在解决家禽互啄与同类相食问题的独特发明——“鸡眼镜”——在美国悄然兴起。这项小巧的装置通常由赛璐珞或铝制成,通过鼻孔固定或绑带佩戴,与传统眼罩不同,它允许鸡只保持前向视野。
其中,玫瑰色镜片版本尤为引人注目,其初衷是利用色彩掩盖血迹,以降低鸡群的攻击性。尽管有制造商曾误认为鸡是色盲,但事实是鸡拥有敏锐的色彩视觉。更有趣的是,部分设计采用了铰链式镜片,确保鸡在低头觅食时视野开阔,而在抬头展现攻击性时,镜片则能呈现红色视野。
作为传统“断喙”的替代方案,鸡眼镜在避免了断喙给鸡只带来痛苦的同时,也兼顾了动物福利。自20世纪初(最早可追溯至1902年)起,鸡眼镜便在美国被大规模生产和销售,成为当时家禽管理中一项兼具创意与人道考量的解决方案。这项百年发明,不仅展现了人类在动物养殖上的脑洞大开与奇思妙想,也折射出对动物福利的早期关注,为现代科技爱好者们提供了一个回顾过去、展望未来的有趣视角。
原文链接:https://en.wikipedia.org/wiki/Chicken_eyeglasses
论坛讨论链接:https://news.ycombinator.com/item?id=44244675
社区中,一场关于“鸡戴护目镜”的讨论引发了广泛关注。有用户最初抱怨文章缺少相关图片,随后有人分享了实物图,引来“比预期更酷”、“时髦”甚至“潮爆了”等幽默评论。然而,讨论很快转向严肃话题,有评论指出这些护目镜是为解决集约化养殖中动物因压力过大而互相残杀的问题,这使得原本滑稽的场景有了深层含义。
随后,话题转向了一个“维基百科图片理论”:若词条右上角无图,则主题不真实或不实用。有用户立即以“算术”和“算法”无图为例进行反驳。理论提出者澄清其仅适用于“物理事物”,并举出“硼”和“内存条”等有图的例子。另一用户补充道,“量子计算”作为抽象概念,其无图正符合物理实体理论。
8. Datalog与miniKanren:解锁智能数据推理 (Datalog in miniKanren)
科技爱好者们,激动人心的进展!一位开发者正为“RealTalk”和“Dynamicland”构建Datalog逻辑编程系统。该系统利用Scheme和miniKanren,并借助支持Wasm GC和尾调用的现代浏览器,确保高效运行。
Datalog作为强大逻辑语言,能高效处理复杂数据关系。例如,有向图分析中,只需定义事实和规则,系统便能自动推导并查询衍生关系,极大简化了图遍历等难题。
其实现亮点:数据以实体ID、属性、值的三元组形式存储,通过高效哈希表索引实现快速存取。
原文链接:https://deosjr.github.io/dynamicland/datalog.html
论坛讨论链接:https://news.ycombinator.com/item?id=44283093
社区上,一位用户分享了一个基于Hoot将Guile Scheme编译为WebAssembly,并在浏览器中运行的极简Datalog实现。随即有评论指出,这并非真正的Datalog,因为Datalog作为Prolog的语法子集,其语法至关重要,若失去其特有语法,则会丧失其中高级功能。另一位讨论者则持不同意见,认为语义比语法更为关键,尤其在Lisp环境中,并强调Datalog仅为纯一阶逻辑,不涉及Prolog的“高级”部分。尽管如此,他也认同当前展示的查询语法不可接受。更重要的是,他指出该实现仅限于二元关系,而正统Datalog应处理N元关系,这才是其偏离Datalog定义的核心原因。他还提供了正统Datalog规则的示例语法以作对比。原帖作者对此反馈表示感谢并完全同意所有批评。他承认查询语法不佳是因“懒惰”所致,并解释其设计初衷是利用不动点分析实现副作用,而非直接查询。作者透露,他曾有过更符合规范的语法实现,但为当前版本“简化”而舍弃。他进一步确认,目前仅支持二元关系确实是其实现未能被视为“正统Datalog”的主要理由,并表示已将扩展至N元关系列入未来的开发计划。讨论最后,有其他用户对该项目表达了浓厚兴趣。
9. AMD AI未来:“Helios”机架,算力新时代启幕 (AMD’s AI Future Is Rack Scale ‘Helios’)



该网页截图展示了一篇题为“AMD的AI未来是机架级‘Helios’”的报道。文章核心聚焦于AMD如何通过其创新的“Helios”机架级系统,布局人工智能未来。Helios系统被定位为AMD面向数据中心和企业级AI计算的高性能集成解决方案,旨在提供强大并行处理和可扩展性,以应对复杂AI负载。这标志着AMD正积极整合其先进GPU技术与软件生态系统,剑指高端AI市场,旨在为客户提供具竞争力端到端AI基础设施,强化AI核心地位。
原文链接:https://morethanmoore.substack.com/p/amds-ai-future-is-rack-scale-helios
论坛讨论链接:https://news.ycombinator.com/item?id=44278746
社区讨论了AMD ROCm生态系统与NVIDIA CUDA的竞争。一位用户指出ROCm在不同用例下表现不一,消费者显卡支持不佳,转用CUDA省去了许多麻烦和时间。另一位用户表示,自2010年CUDA在科学计算领域兴起以来,AMD的软件劣势问题就一直存在,并质疑AMD为何15年后仍未能复制成功模式,认为NVIDIA的软件生态和用户心智优势已难以撼动。
然而,也有观点反驳称,根据最新Top500榜单,前十名中有四套系统运行AMD Instinct卡,表明NVIDIA在小型系统有优势,但在集群领域并非如此,只要有专业团队支持,性能仍可超越市场影响力。对此,有人认为Top500的比较无关紧要,因为AMD必须为获得数亿美元订单的大客户提供直接支持;NVIDIA虽也如此,但其消费级产品也能做到“开箱即用”。该评论还强调,AI市场(如xAI的Colossus集群)规模远超HPC,利润和部署量都更大。
讨论中还提到,HPC对AMD而言可能是一把双刃剑,它需要投入大量定制化支持,甚至派遣工程师解决问题,这可能分散了AMD在更广阔的AI市场上的精力。总结性观点指出,即便AMD愿意投资软件,也需要有竞争力的GPU架构支持,这并非易事。