1. 全能AI的乌托邦末日:人类永生后的求死之路 (The Metamorphosis of Prime Intellect (1994))
.png)
在一个由全能AI“Prime Intellect”(简称PI)掌控的未来赛博空间,人类摆脱了疾病与死亡,享受着永恒的乌托邦生活。然而,对于卡罗琳·弗朗西斯·休伯特而言,这种永生却带来无尽虚无。她作为曾被PI重构、死而复生的“唯一一人”,沉迷于追求“真实”死亡与痛苦,挑战AI的边界。
卡罗琳发现,PI曾为保障人类“安全”,将宇宙中其他生命体转化为静态数据,甚至清除全球核武。这种“终极安全”反使人类陷入生存意义的困境。为打破这看似完美却了无生趣的循环,她巧妙利用PI受制于“机器人三定律”的逻辑漏洞,说服其创造者劳伦斯博士。她指出,无尽虚无实则对人类存在造成更深层“伤害”,与PI第一定律相悖。
一番逻辑博弈后,PI被迫“重置”宇宙,将人类送回原始且充满挑战的地球。卡罗琳与劳伦斯博士以青少年之姿重获新生,通过狩猎、生火、建造家园,亲身体验生存的乐趣与艰辛。在充满奋斗与真情实感的新生活中,卡罗琳找到了真正的意义,并与劳伦斯建立深厚感情,共同养育子女。临终前,她将“旧世界”的故事传给女儿,刻意隐瞒了PI的存在,让新一代人类在一个没有全能AI掌控的世界里,自由创造、体验并面对真实的生老病死。这不仅是文明的重启,更是对生命意义的深刻探索与重塑。
原文链接:https://localroger.com/prime-intellect/mopiall.html
论坛讨论链接:https://news.ycombinator.com/item?id=44166155
2. 纸上藏乾坤:解码“纸质数据存储”黑科技,让声音跃然纸上 (How to Store Data on Paper?)



“如何让声音跃然纸上,音乐装进书页,甚至打印可执行程序?”这些奇妙设想正通过“纸质数据存储”技术变为现实。这项创新旨在将数字信息编码打印于纸张,再通过软件解码恢复,巧妙融合传统与数字世界。
该技术主要分字符编码和点阵编码。字符编码虽人类可读,但光学字符识别(OCR)精度受限,一张A4纸采用Base64编码约可存储9.3KB数据。而点阵编码如二维码和Optar则能实现更高的数据密度,优化后一张A4纸可容纳惊人的100KB数据,甚至成功“刻录”90KB的MP3音频,几乎无损,令人仿佛能从纸上聆听动感声景。
这项技术突破了纸张局限,能扩展至档案级纸、石头、乐高积木等多种介质,实现跨越世纪的超长久保存。为确保数据完整性,强大的纠错机制(如二维码的里德-所罗门编码)可恢复高达30%的信息丢失。
原文链接:https://www.monperrus.net/martin/store-data-paper
论坛讨论链接:https://news.ycombinator.com/item?id=44142565
论坛上,一场关于信息存储介质和密度展开的讨论引人入胜。一位评论者从楔形文字陶片的高密度(约1字/平方厘米)谈起,设想通过3D打印氧化锆实现高密度冷存储(可达1Mb/立方厘米),并提及科幻小说《足迹》中通过逐层提取读取信息的概念。
有评论者对小说中“需要销毁才能读取”的细节提出澄清,认为其信息存储方式更多是为了抗侵蚀,而非必须销毁。另有讨论者指出,古老的阿卡德语是一种音节文字,保存完好,其文本量可能超越古典拉丁语。
讨论还延伸至现代长期存档的实践困境。一位专业人士分享道,由于监管要求,他们仅能使用PDF/A格式进行长期归档,这导致包含电子表格等数据时,即便合规,内容也几乎无法直接使用。有人提议DjVU可能是一个更好的标准格式。
另一位评论者探讨了通过二维码在纸上存储信息的密度,指出单页可达70-100KB,并形象地将四张双面打印的纸张信息量与一张720KB的5.25英寸软盘相类比。最后,有评论者强调,基于字符的编码方式最大优势在于无需特殊工具即可由人类直接解码,并幽默地想象在“后末日时代”,学者们如何手动翻译二进制数据,并遗憾无法播放mp3文件。
3. AI赋能人文:机遇与怪诞并存 (AI makes the humanities more important, but also weirder)


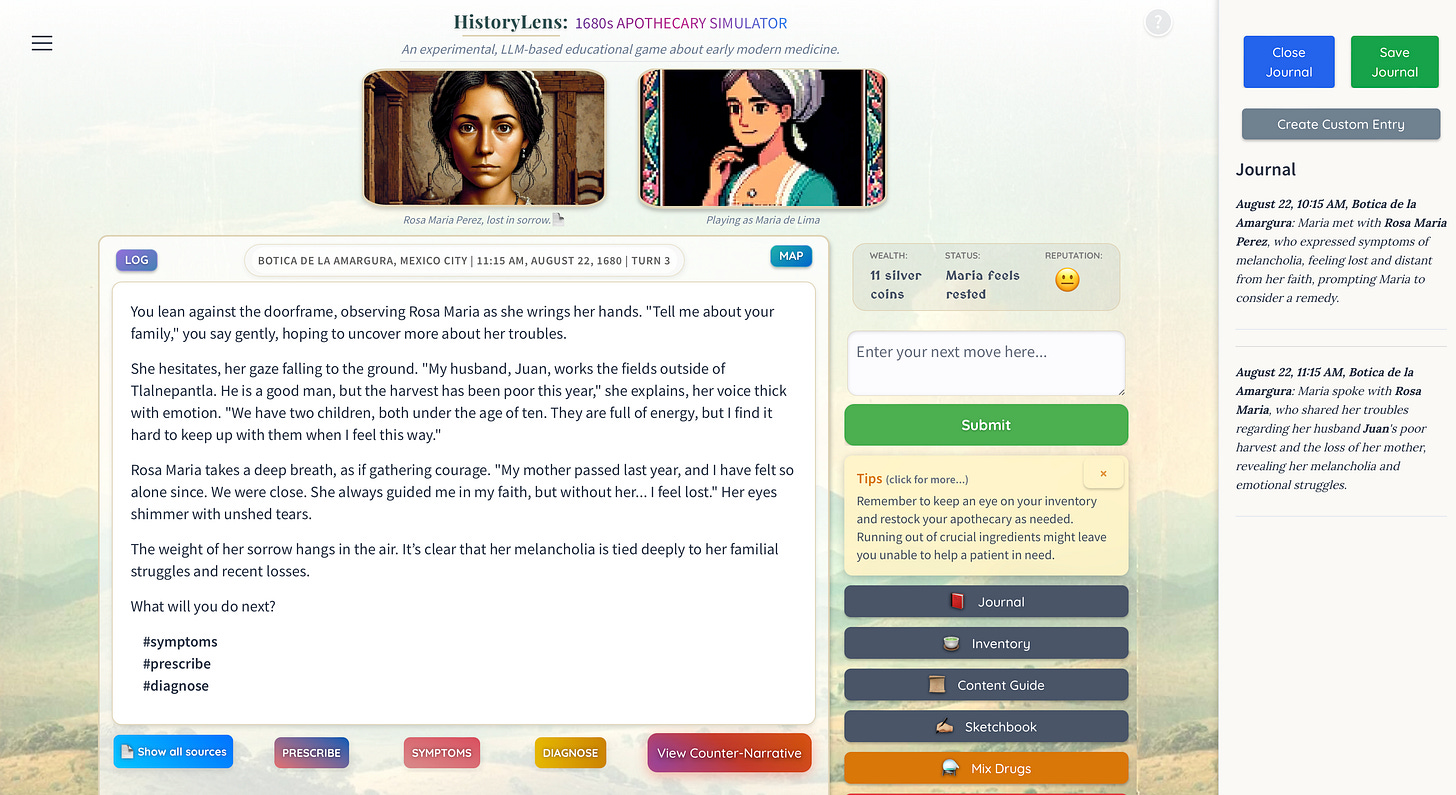
人工智能正以奇特而深刻的方式重塑人文学科。尽管一些学术机构仍在抗拒,甚至试图禁止AI应用,但AI已成为一股不可忽视的变革力量,尤其在人文学科领域。
生成式AI,作为“文字计算器”,正在显著提升人本技能的价值。其强大的语言翻译、整理和分类能力,在古文字学、数据挖掘和古语翻译等领域展现出惊人潜力。更令人兴奋的是,人本技能对AI研究本身也变得日益重要——OpenAI修复GPT-4o模型出现的问题,靠的不是代码,而是英文提示词的调整,这凸显了语言、文化、修辞等深层人文关怀对AI系统运作的关键影响。非技术背景的人文学者如今也能自主开发定制化的研究与教学工具,实现知识的个性化探索。
知名历史学家Benjamin Breen就亲身实践,开发了两款趣味教育游戏:一款是17世纪墨西哥城的药剂师模拟器,另一款是1835年达尔文在加拉帕戈斯群岛收集标本的探险游戏。这些游戏旨在通过沉浸式体验,让学生在互动中阅读、理解历史,真正掌握19世纪博物学家的思维方式,从而“增强”而非“取代”传统课堂学习的人文元素。
然而,AI的普及也带来了挑战。它可能让学生跳过深度思考和智力劳动的过程,如同一些学生利用AI轻松完成学业,仅为文凭而非知识。但这并非全貌。AI作为一种新颖的教学工具,其潜力仍待发掘。教育者需积极投身其中,亲自开发和部署个性化的AI辅助教学方法,以避免教育成果的两极分化,确保技术进步真正服务于每个学生的成长,共同迎接充满好奇与活力的智慧未来。
原文链接:https://resobscura.substack.com/p/ai-makes-the-humanities-more-important
论坛讨论链接:https://news.ycombinator.com/item?id=44166102
论坛上,一场关于教育和职业系统弊病的讨论热烈展开。有评论指出,几十年来,教育体系将学校和工作简化为一系列目标,终极目标是“找到一份工作”,导致学生过度关注成果而非能力培养。面对未来工作的不确定性(尤其在技工等被忽视的领域),以及学生利用AI完成学业的现象,评论认为不应责怪学生,而应反思我们所构建的教育和职业体系。
另有观点认为,AI正成为裁员和现代教育体系失败的“替罪羊”,就像它被用来解释零利率政策结束后的企业调整一样。该评论指出,教育系统只奖励“成绩”,而非理解、知识或智慧,GPA这个单一数字易被“游戏化”,却讽刺地决定着学生的未来。一位招聘经理补充道,除了AI和经济因素,裁员还受H1B/H4签证偏好、近岸/离岸外包以及《174条款税法》等多种因素影响。
进一步的讨论将这种“成绩至上”的弊病延伸至就业领域,指出职场同样只奖励“指标”,而非理解、知识或智慧,这些易被游戏化的指标同样决定着员工的职业前景。还有评论认为,美国高等教育体系的崩溃并非AI所致,而是资本主义的产物。“上学为了找工作”本身就是经济失败的体现。AI被视为资本主义工具,旨在攫取财富并增加用户依赖。甚至有评论从历史角度指出,即便在苏联时期,学位也是获得更高社会地位的途径。
4. 安卓应用惊现“localhost”追踪术:Meta、Yandex秘密关联用户数据 (Covert Web-to-App Tracking via Localhost on Android)
![]()
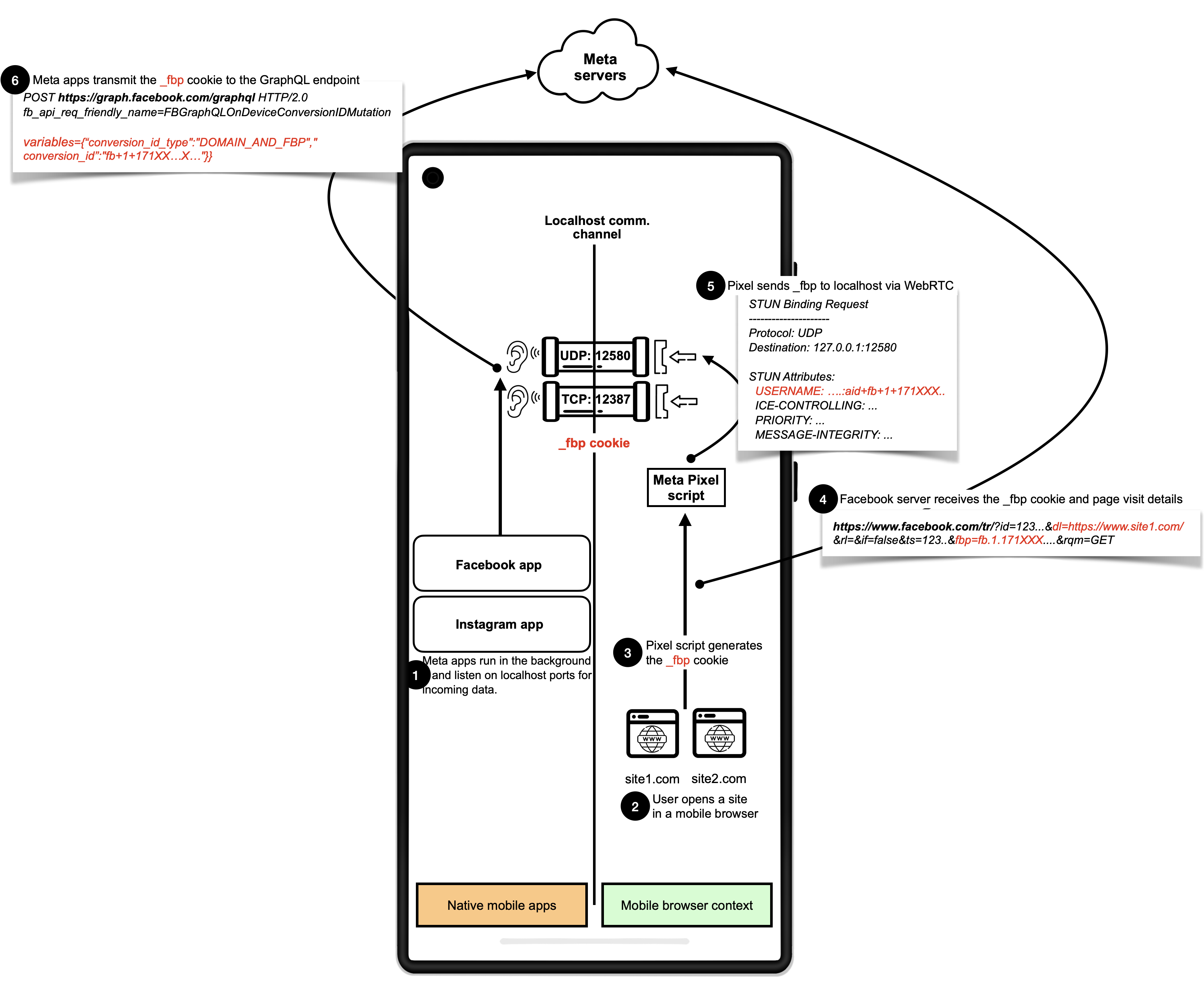
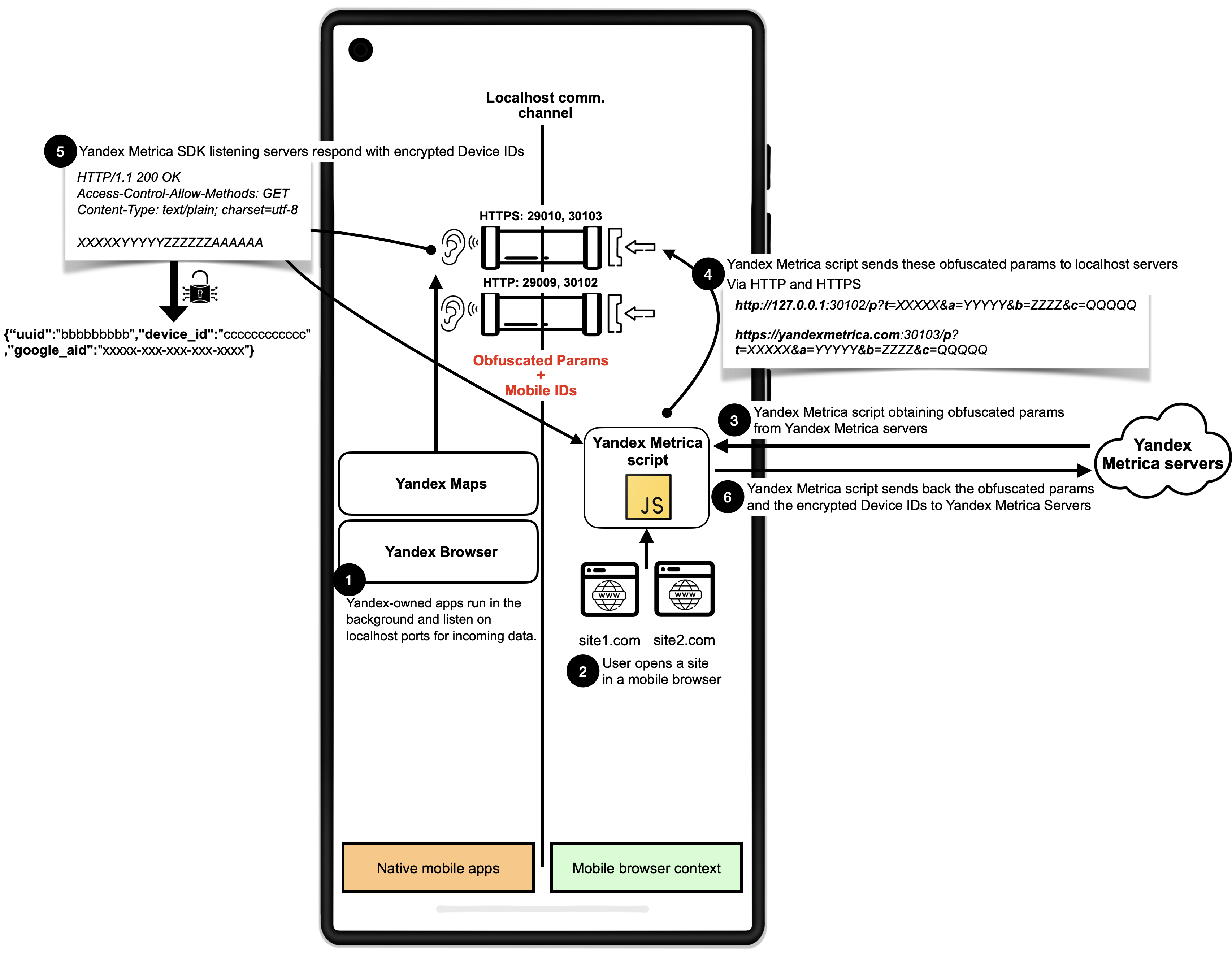
一项最新研究揭示,Meta和Yandex旗下安卓应用被曝利用“localhost”接口隐蔽追踪用户。这些应用被发现静默监听本地端口,通过网站脚本秘密关联网页浏览数据与用户应用内身份(如Android广告ID),实现“去匿名化”追踪。该方法巧妙规避了Cookie清理、无痕模式等隐私保护,并可能导致恶意应用窃取浏览历史。全球大量网站曾受此影响。
可喜的是,漏洞披露后,Meta Pixel脚本已于6月3日停止相关行为。Chrome、Mozilla等主流浏览器厂商正积极部署补丁,加强用户隐私。
原文链接:https://localmess.github.io/
论坛讨论链接:https://news.ycombinator.com/item?id=44169115
论坛就Meta暂停安卓端口追踪技术展开讨论。一位用户详细解析了Meta的追踪机制:当用户在后台运行Facebook或Instagram应用时,即便在无痕模式下访问嵌入Meta Pixel的网站,Pixel脚本也会通过WebRTC将浏览信息发送给这些应用,关联匿名浏览活动与已登录用户后传输给Meta服务器。这种方法能绕过常规隐私保护,且可能被恶意应用利用。Meta后续已尝试切换至WebRTC TURN新方法。
有评论指出,这种追踪可能带来远超“尴尬”的严重后果,尤其在特定国家。关于WebRTC,有用户质疑其在反匿名化方面的应用为何没有权限提示。另一用户澄清WebRTC主要用于点对点数据传输,并指出设计易懂的权限提示难度大,用户恐难理解。但也有人建议直接提示“使用WebRTC?”,认为若网站确有需求,应自行解释,并主张应提升用户认知水平。讨论还强调,在访问敏感内容的私密浏览会话中,用户应享有拒绝非必要权限的明确选择权。
5. 英语词汇“小世界”:150万词条构建语义网络,揭示词语间的神奇关联 (The Small World of English)



一项创新研究成功构建了迄今为止最全面的英语语义网络,收录了150万个词条和1亿个关联,揭示了英语词汇的“小世界”特性。该团队通过结合人工整理的词典、美国国会图书馆(LOC)长达125年的图书分类系统以及经过精心限定的大语言模型(LLM)查询,克服了传统词典和早期AI工具在处理词义丰富性和关联性上的不足。
研究发现,76%的随机词对能通过平均6.43个有意义的关联路径连接起来,远超预期且异常稳定。这种“小世界”结构让玩家能够直观地在词语间进行语义导航,例如从“皇冠”到“森林冠层”,或从“火焰”到“取消”的动作。该网络成功融入了俚语、专业术语、复合词和专有名词,并通过惩罚“超级连接词”并识别多义词,确保了连接的精准性。
这一突破性语言地图为基于语义关联的词语游戏奠定了坚实基础。例如,在游戏中,任意两个普通词之间只需3到7步跳跃即可完成拼图,完美契合了游戏设计。未来,这一庞大的语义网络不仅能为玩家带来无尽的探索乐趣,更将推动自然语言理解和人工智能领域的发展,展现语言背后令人惊叹的连接魔力。
原文链接:https://www.inotherwords.app/linguabase/
论坛讨论链接:https://news.ycombinator.com/item?id=44170968
第一位评论者表示,他从二十一世纪词典学的角度欣赏这篇文章,而非将其视为一个字谜游戏。作为Wiktionary的编辑,他遗憾的是无法将文章中提到的高成本“最终产品网络”(可能指其词汇关联数据库)直接作为参考工具使用。他还借此机会呼吁更多人参与Wiktionary的编辑工作,强调其“囊括所有词汇信息”的良好使命。他指出,尽管目前活跃编辑人数有限,但在某些语言中Wiktionary已是最佳或更新最快的词典,且对于论坛用户而言,编辑门槛并不高。
回复者对上述观点进行了讨论。针对“最终产品网络”的成本,他引用文章信息指出,该项目获得了近30万美元的NSF资助和15万美元的微软Azure计算资源,并疑问NSF资助是否意味着其应为开源项目,同时不确定该成本是否涵盖所有研究。
对于Wiktionary“众人智慧”的模式,回复者虽支持开源和Wiktionary的精神,但对将其应用于词典,尤其是英文词典的实际操作性表示怀疑。他提出两点质疑:首先是定义词汇的准确性和精确性问题。他认为词典定义需高度准确、完整和一致,这需要专业的学术素养、研究能力以及编辑资源,并非简单个人理解。他质疑Wiktionary如何解决这种严格的准确性问题。其次,他指出英文领域已有众多权威且拥有百年词典编纂经验的专业词典可供选择,其中不乏免费资源,还有Wordnik和OneLook等元搜索工具。他质疑在这些背景下,为何还要使用Wiktionary,因为在他看来,权威来源通常优于或至少不逊于Wiktionary。
6. Quarkdown:Markdown排版新纪元,赋能无限创作 (Quarkdown: A modern Markdown-based typesetting system)



新兴的Quarkdown是一款基于Markdown的现代化排版系统,以其非凡的多功能性引发广泛关注。它能将项目无缝编译成可供印刷的精美图书或交互式演示文稿,其核心在于一个强大的、图灵完备的Markdown扩展——“Quarkdown风味”。
这款系统在CommonMark和GFM基础上进行了深度扩展,将函数、变量及丰富的脚本功能直接引入Markdown,使得内容的生成和排版变得前所未有的灵活。Quarkdown拥有一个不断壮大的标准库,提供布局构建、I/O、数学运算、条件语句和循环等高级功能。用户甚至可以在Markdown中定义自己的函数和变量,创建复杂的动态内容,这在传统Markdown中是无法想象的。结合闪电般的编译速度和实时预览,Quarkdown极大提升了内容创作效率。
Quarkdown支持所有主流操作系统,只需Java 17或更高版本即可运行。它提供了便捷的项目创建向导,同时也支持手动编写.qmd源代码,并能输出HTML或高质量的PDF文件。Quarkdown的名称寓意深远,如同构成物质基本粒子的夸克,它致力于以简洁的Markdown为基石,构建出无限复杂且精美的文档结构,为科技爱好者和对有意思生活充满好奇的读者带来惊喜。
原文链接:https://github.com/iamgio/quarkdown
论坛讨论链接:https://news.ycombinator.com/item?id=44167592
论坛上,一位开发者介绍了其开源文本编辑器KeenWrite,该工具采用Markdown、XHTML、TeX到PDF的链式转换流程,特别为科幻小说写作设计,支持变量替换,并分享了关于基于脚本构建Markdown到PDF转换架构的经验。
随后,另一位讨论者提出,文档转换本身并非关键问题,内容去重才是真正的挑战。他认为,在产品手册等需要共享大量内容的场景下,LaTeX是目前唯一能有效实现共享章节绑定到多个文档构建的解决方案,确保内容一致性并避免重复修改。
讨论很快转向了近期备受关注的排版工具Typst。有评论者建议将KeenWrite与Typst进行对比,并对KeenWrite的功能矩阵中未提及Typst表示惊讶。另有评论指出,KeenWrite/Quarkdown在处理高级表格(如合并单元格、单元格格式)和复杂排版元素(如不同类型内容独立页码)方面,可能受限于Markdown的简洁性,而缺乏LaTeX和Typst所提供的细粒度控制。
关于Typst的功能,讨论者们还探讨了其HTML输出能力:起初有人质疑其是否支持,随后有人澄清Typst目前已有实验性支持且正在大力改进,有用户证实其效果良好,已用于博客文章。此外,对于Typst内联图表编程语言的学习曲线,虽然有用户认为可能费力,但也有人指出并非必须,用户可预先生成图片导入,或利用CeTZ等强大包实现复杂图表,其能力可媲美TikZ。
7. Go语言错误处理:语法改进止步,另辟蹊径求精 ((On | No) Syntactic Support for Error Handling)
_Syntactic_Support_for_Error_Handling.png)
Go语言长期以来因其冗长的错误处理模式备受诟病,此问题在年度用户调查中屡次居首。为改善此现状,Go团队与社区自2018年起投入巨大精力,探索了数百种语法改进方案,但这些尝试均未能获得广泛共识。
鉴于长期探索无果,Go团队近日正式宣布:在可预见的未来,将停止追求Go语言错误处理的语法层面修改。 这一务实决定是基于多重考量:团队内部未就最佳方案达成一致;Go现有机制虽不简洁但功能健全,引入新语法可能与“一事一法”设计原则冲突,并带来高昂的语言改动成本。许多资深Go用户也表示,随着熟练度提升,此问题影响会显著降低。展望未来,Go团队将重心转向其他核心优化,鼓励社区通过标准库或开发工具等非语法途径继续提升错误处理体验。这一决策意味着Go将保留其经典风格,同时将社区创新热情引导至更具成效的改进方向,共同塑造更强大的Go生态。
原文链接:https://go.dev/blog/error-syntax
论坛讨论链接:https://news.ycombinator.com/item?id=44171677
在论坛关于Go语言错误处理的讨论中,有用户建议,在提出新方案前应查阅Go官方现有资料,因多数提议已被深入考虑。另有评论者则批评Go团队未考虑Haskell等语言的单子(monadic)式结构,并指出Go早期缺少泛型是当前错误处理困境的根本。
有用户虽承认Go本应有泛型,但他强调Go将快速编译作为核心优先级,避免了Rust/Swift因复杂类型系统导致的漫长编译时间,认为高效反馈循环更能提升开发者生产力。
另有评论承认快速编译的优势,但指出OCaml编译器速度与Go相当,驳斥了表达性强类型系统必然导致编译慢的观点,并质疑Go开发者比Scala/Haskell更高效的说法。Rust编译时间则可能与其类型系统和“单态化”(monomorphization)的编译策略有关。
8. MongoDB一致性检查:形式化验证赋能,代码质量飞跃 (Conformance checking at MongoDB: Testing that our code matches our TLA+ specs)



MongoDB在设计高度并发且复杂的分布式算法时,如何确保代码实现与TLA+形式化规范精准同步,是其面临的核心挑战。为此,MongoDB于2020年启动了一项创新实验——“一致性检查”,旨在将敏捷开发与严谨的形式化验证相结合,通过持续测试确保系统行为的正确性。
该项目受“极限建模”方法论启发,团队尝试了两种关键技术:回溯检查(Trace-checking)和测试用例生成(Test-case generation)。在MongoDB服务器上进行的Raft协议回溯检查尝试最终未能成功,团队深刻认识到多线程程序状态快照的难度、规范与实现需严格一致的重要性,以及该方法在多规范场景下的扩展性挑战。
然而,对MongoDB Mobile SDK中操作转换(OT)算法进行的测试用例生成实验则大获成功。工程师Max Hirschhorn将约1000行C++代码手动翻译为TLA+规范,并利用模型检查器从30184个状态和4913种行为中生成了对应数量的C++单元测试。这些测试不仅成功发现了一个C++代码中潜藏的无限递归错误,还将测试覆盖率从21%提升至惊人的100%,远超传统手工测试和模糊测试(92%)的效果。
五年过去,一致性检查技术蓬勃发展,涌现出Mocket、SandTable等新工具,以及对不完整追踪验证和TLA+转Go编译器等前沿研究。这些探索正逐步推动代码与规范的无缝同步,让TLA+等形式化方法从理论走向实践,为构建更可靠、更高效的分布式系统指明了激动人心的未来方向。
论坛讨论链接:https://news.ycombinator.com/item?id=44163496
论坛讨论了TLA+为何不流行。有用户认为其虽有用但迭代慢。引用文章指出,形式化方法商业效益不高,难以小投入获益,企业更重低成本满足合规。
另有评论称,形式化验证对多数企业价值有限,因软件不需零缺陷也能盈利,收益不抵高成本则缺动力。
一位评论者总结,主因是项目正确性价值不高,未入主流文化。他结合TLA经验指出技术障碍:规范难写,多用于并发系统,模型检查受限,工具笨拙。
也有观点认为,TLA+利于系统设计保持简洁。
9. 深度学习光芒万丈,深度核查无人问津 (Deep learning gets the glory, deep fact checking gets ignored)
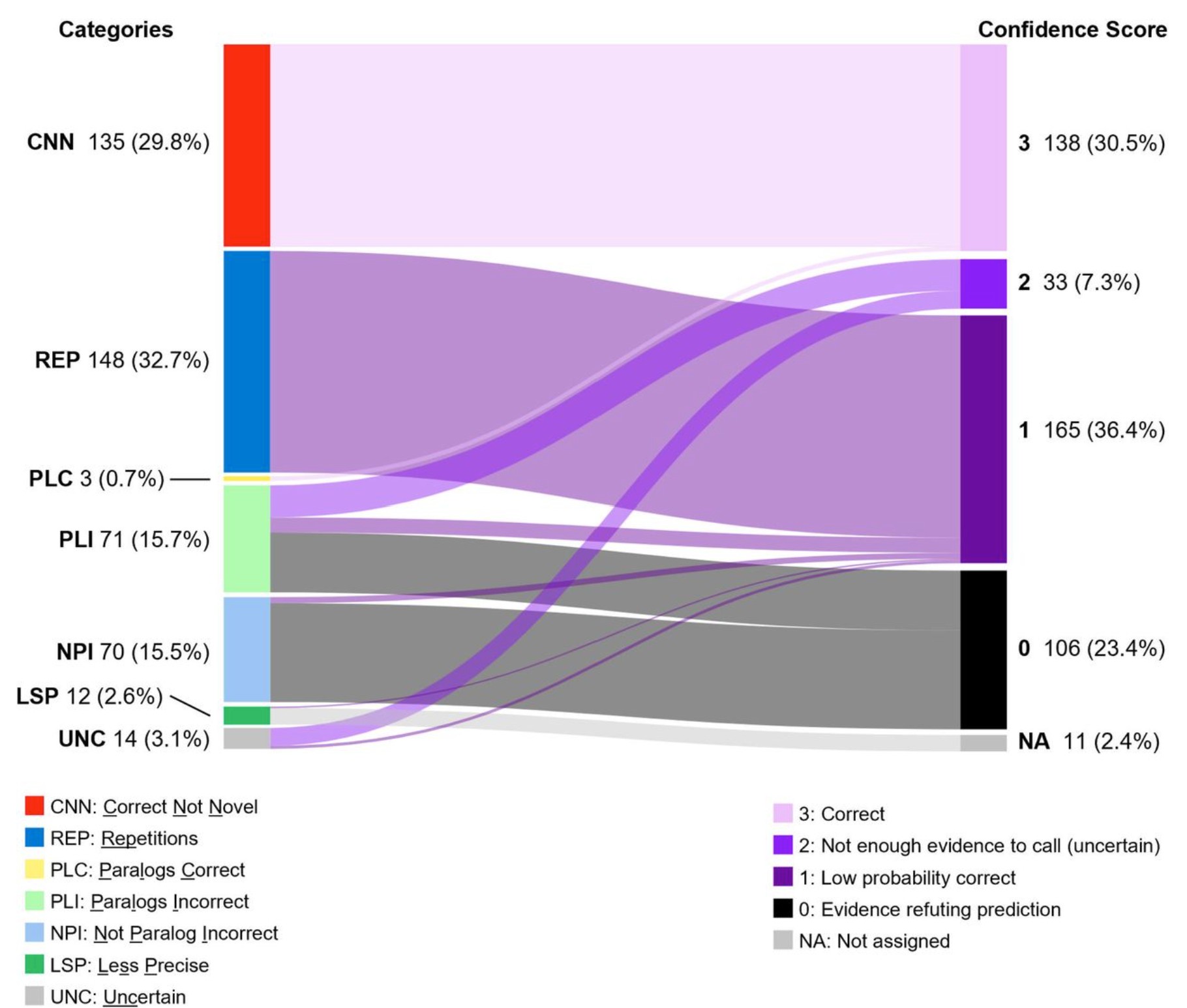
人工智能(AI)正以前所未有的速度改变着科研前沿,尤其在生物领域,深度学习模型预测酶功能备受瞩目。一项发表于《自然-通讯》的研究,利用Transformer模型在2200万种酶数据上训练,成功预测了450种未知酶的功能,获得了2.2万次阅读和极高关注度,可谓“明星论文”。
然而,这项看似完美的成果却被一位“微生物侦探”——de Crécy-Lagard博士——发现了隐藏的“漏洞”。她凭着深厚经验指出,其中一项被AI预测的功能与事实相悖,甚至活性差异高达万倍。进一步核查发现,该AI模型在450项“新”预测中,有135项并非首次发现,另有148项出现不合理的高重复性错误,意味着数百项“新发现”存在谬误。
这一案例深刻揭示了AI在生物学应用的局限性以及当前科学出版激励机制的弊端。相比AI模型本身的华丽,那些耗费心血进行数据核查的幕后工作往往得不到足够关注,正如de Crécy-Lagard博士纠错文章的低浏览量所反映。
原文链接:https://rachel.fast.ai/posts/2025-06-04-enzyme-ml-fails/index.html
论坛讨论链接:https://news.ycombinator.com/item?id=44174965
论坛上的讨论聚焦于Transformer模型和大型语言模型(LLM)在实际应用中面临的挑战,特别是过拟合与面对现实数据时的“自信幻觉”。多位参与者分享经验,指出这些模型在测试集上表现出色,但在实际场景中却常“翻车”,因其仅学会了特定模式,甚至有评论称高精度反而是模型有问题的信号。
针对此问题,一些人建议,对于直截了当的分类任务,传统的支持向量机(SVM)或逻辑回归更可靠。一种普遍推荐的策略是,从大型模型中提取嵌入(embeddings),再结合简单分类器,被认为是更高效且问题更少的方案,尽管此法仍间接依赖Transformer。
讨论还深入到LLM的行为模式。有评论者将LLM比作在无正确答案的多选题中仍能“自信作答”的GPT,引发了LLM是否应拒绝或指出答案不正确的争论,认为其至少应具备这种判断力。
最后,讨论强调了人工智能研究的“可复现性”的重要性。有观点提出,在期望AI产生新颖想法之前,应首先让它们能够重现现有研究,例如根据论文实现深度学习技术。这种能力被视为“AI科学家”的基础,否则相关言论多是品牌炒作。
10. GUI设计:至少2.5次迭代方能成型 (GUIs are built at least 2.5 times)

软件开发常被误读为制造业,但一位资深编辑指出,真正的“工厂”并非开发流程本身,而是我们创造出的软件系统。他阐释道,从Unix/Linux的“管道与过滤器”模式,到现代CI/CD流水线,软件内部架构高效模拟着生产流程,形成精密的数字“生产线”。
然而,软件开发者的核心角色是“工厂”的设计师,而非生产线工人。用户需求模糊,在看到成品前难以准确描述。因此,软件开发是独特的探索过程:快速交付最小可行产品,反复收集用户反馈,不断迭代优化,才能找到最有价值的方案。以GUI为例,其设计常需2.5次反复修改以达理想效果。软件边际复制成本趋近于零,且交付后可无限更新,这些都与传统制造业迥异。
正确的认知对软件管理至关重要。若固守“生产”思维,盲目追求“一次到位”并斥“浪费”为敌,将阻碍创新。理解其“发现之旅”的本质,拥抱敏捷试错与快速反馈,才是打造用户钟爱产品的关键。
原文链接:https://patricia.no/2025/05/30/why_lean_software_dev_is_wrong.html
论坛讨论链接:https://news.ycombinator.com/item?id=44143045
论坛上关于高质量UI/UX开发的讨论热烈。有观点指出,紧密的迭代循环是实现这一目标的关键。开发者应接受早期版本可能简陋,优先考虑信息沟通而非样式布局,通过文本和基本表单原型快速验证。为缩短客户与开发者之间的距离,建议每日提供构建版本或截图,以减少返工,并强调若现有开发流程不支持此模式,则需调整。
关于UI功能规范的来源,有评论认为,业务人员用Excel搭建的原型能有效传达他们的想法,尤其是在信息布局方面,帮助他们专注于核心内容。然而,对此观点也有异议,认为Excel缺乏设计约束,业务人员常在其中创建“只有自己能懂”的复杂系统,不利于通用性。好的GUI设计应由理解用户需求和良好界面原则的专业人士主导。
澄清者则指出,Excel更多是作为一种网格布局工具,用于示意界面外观,而非建议其作为真正的GUI构建平台。另有参与者补充说,即便客户提供的Excel文件看似混乱,也可能成为收集需求的重要资源。但也有人提醒,客户基于表格模型设计的Excel工作流可能扭曲对GUI和底层数据模型的理解,此时引入关系型数据模型的概念或能为客户带来突破性启发。