1. OpenAI怒斥法院:保存所有ChatGPT聊天记录,包括已删除内容! (OpenAI slams court order to save all ChatGPT logs, including deleted chats)



OpenAI目前正积极应对一项法院指令,该指令要求其必须保存所有ChatGPT的用户日志,包括已删除的聊天记录以及通过API业务产生的敏感对话。此举源于多家新闻机构(如《纽约时报》)就版权侵犯提起诉讼,并指控OpenAI销毁相关证据。
OpenAI对此裁定表达了强烈异议,认为法院在缺乏充分证据的情况下仓促发布了这项“史无前例且范围广泛”的禁令,仅凭新闻机构的“猜测”就要求他们保留原本会被删除的数据。该公司强调,这项命令已严重阻碍其履行对全球数亿ChatGPT用户(包括免费版、Plus版、Pro版及API用户)的隐私承诺,即允许用户自主管理和删除个人对话。
OpenAI坚称其从未故意销毁任何数据,亦无证据表明涉及版权侵权的用户会更频繁地删除聊天记录。公司指出,此命令不仅对其造成巨大的工程和经济负担,更可能导致其违反用户隐私协议及全球隐私法规。该事件已引发用户广泛担忧,许多人认为这严重损害了数据安全与合同信任。目前,OpenAI正全力争取撤销该命令,以捍卫用户隐私权,并寻求在版权保护与AI技术发展之间找到新的平衡点。
论坛讨论链接:https://news.ycombinator.com/item?id=44185913
论坛上,一位用户对纽约时报诉讼中可能出现的法院指令表示深切担忧。他认为,如果法院为模糊指控而命令OpenAI保留数据,这等同于牺牲数亿乃至数十亿网民的隐私权和言论自由。他提出了一系列设问:未来互联网服务提供商和谷歌是否也会被迫记录并长期保留所有用户活动?这种做法会侵蚀个人身份,甚至使人类丧失个体性,并质疑谁将承担巨额成本。
然而,有评论者指出,法院在现有案件中本就有权要求当事方保存证据,例如在谷歌垄断案中也曾出现过。此类要求发生在“证据披露”阶段,且必须基于原告已遭受的具体损害,而非仅仅是未来可能发生的“坏事”或模糊指控。因此,没有具体不当行为指控的案件会被驳回。这位评论者强调,此次不同之处仅在于OpenAI被要求保留的潜在证据数量。
另有讨论指出,OpenAI作为用户数据的保管者,负有配合法院指令的责任。为了让原告识别出具体的侵权聊天内容,他们需要首先获取OpenAI的数据,而这正是法院要求OpenAI保存数据的原因。此外,有用户对OpenAI的数据收集模式表示了“蜜罐”式的讽刺,也有人质疑在隐私权讨论中是否考虑了来自OpenAI本身的隐私问题。
2. BEAM宝典:十年磨砺,解百万交易之困 (Why I wrote the BEAM book)


在科技浪潮中,一位资深工程师十年磨一剑,终于让《BEAM宝典》面世。曾亲历BEAM系统15毫秒停顿导致数百万交易停滞的作者Happi,深知一份及时可靠的参考手册对工程师的价值,因此他决心打造此书,旨在帮助同行们在“咖啡变凉前”解决问题。
这部宝典的诞生之路并非一帆风顺。自2012年10月12日项目启动,历经两次出版商合作中断、文件管理困境,甚至遭遇百万行代码的重构,挑战重重。但Happi凭借对BEAM虚拟机底层逻辑的执着求索,以及GitHub社区力量的鼎力支持(如24小时内即有贡献者加入、#113的暖心鼓励),使其得以坚持。这本书不仅是他对技术深度的渴望,也成为了BEAM/Erlang大会上被反复引用的权威资料。
《BEAM宝典》深入剖析了调度器、内存管理、垃圾回收、数据表示、编译器与虚拟机机制等BEAM核心技术,旨在为Erlang或Elixir系统开发者提供一份权威指南,免去他们大海捞针般的资料查阅之苦。最终,作者在Code Beam Stockholm大会的真实截止日期前,将这份凝聚心血的作品印刷成册,宣告其V1.0版本正式面世。这不仅彰显了“坚持胜于完美”的理念,也证明了专注、社区协作与清晰的目标是成功的关键。现已在亚马逊上架,并持续接受全球开发者的贡献与反馈,它无疑将成为无数工程师解决实际问题的得力助手。
原文链接:https://happihacking.com/blog/posts/2025/why_I_wrote_theBEAMBook/
论坛讨论链接:https://news.ycombinator.com/item?id=44179257
这场论坛讨论围绕技术书籍的撰写与出版展开,尤其是小众(niche)主题的发行策略。一位评论者表示,他对深入理解底层逻辑的追求,促使其购买相关书籍,但也感叹作者常难以找到自身热情与读者需求之间的交集,例如出版商倾向于面向初学者的Java书籍,而作者更想写关于类加载器等专业话题。
另一位出版了三本书的作者分享经验称,作者要么选择自主出版,要么就得迎合出版商的商业需求。他指出,多数出版商偏爱销量大的入门级读物,而像O’Reilly这类出版社才可能对小众技术内容感兴趣。不过,他强调,如今自主出版已变得非常便捷,作者可以轻松在各大平台在线销售自己的作品,这意味着如果想写小众内容,就应做好自主出版并自行推广的准备。
一位出版了五本书的作者也印证了这一观点,即使他的最新著作与某出版商的使命高度契合,最终该出版商仍放弃了,迫使他选择自主出版。他通过LeanPub、亚马逊等多种渠道发行。随后,讨论转向自主出版的销量和营销。这位作者表示,尽管其主题小众,但他通过LinkedIn、邮件列表等建立的社区,仍能带来可观的销售额,并持续通过博客推广书籍。
3. Chrome新规:公网访问本地网络需用户授权,全面掌控你的网络安全 (A proposal to restrict sites from accessing a users’ local network)
谷歌Chrome团队正积极推进一项名为“本地网络访问”的新提案,旨在大幅提升用户本地网络安全。当前,恶意网站可能利用浏览器漏洞探测并攻击用户的本地设备。为应对此风险,新方案核心在于,公网网站访问本地私有IP时需用户明确授权。浏览器将弹出权限请求,由用户自主决定是否允许。
这项变革相较此前因复杂性而搁置的“私有网络访问”方案更易推行,因为它主要要求网站进行适配,而非本地设备。为兼顾智能设备互联需求,提案允许开发者在fetch() API中指定targetAddressSpace,从而即使在本地网络缺乏HTTPS的环境下,也能通过用户授权进行安全通信。此举不仅有效防范潜在网络风险,更赋予用户对其本地网络访问的全面掌控,预示着一个更安全、更智能的上网体验即将到来。
原文链接:https://github.com/explainers-by-googlers/local-network-access
论坛讨论链接:https://news.ycombinator.com/item?id=44183799
论坛上关于网站探测本地IP的讨论,围绕着对当前安全机制CORS(跨域资源共享)的理解和其局限性展开。
一位评论者担忧网站随意探测本地IP并发送HTTP请求的风险,建议浏览器弹出窗口征求用户许可,以增强对本地设备的控制。然而,有观点指出,本地网络设备已受CORS保护多年,通常要求目标服务器返回特定头部来同意请求。新的提案旨在进一步收紧这一机制,即使网站和本地设备都同意通信,也需额外征求用户明确许可,以防范类似Facebook应用秘密与手机应用通信的潜在恶意合作。
讨论中,有用户质疑CORS是否仅限制JavaScript上下文获取响应,而请求本身仍会发生,从而可能通过精心构造的请求(如针对易受攻击的打印机)触发远程设备上的任意代码执行。对此,另一评论者解释,浏览器会先发送一个“预检”(OPTIONS)请求,这使得客户端难以完全控制恶意负载。
然而,也有人指出,某些HTML标签(如<img src="...">)可以在没有CORS介入的情况下触发本地网络GET请求,这被称为CSRF(跨站请求伪造)攻击,只要目标终端不验证请求中的令牌。CORS主要保护的是未经授权的XHR(XMLHttpRequest)请求。评论者普遍认为,这些都是OWASP(开放式Web应用程序安全项目)中几十年前就已强调的基础知识,但令人惊讶的是,即使在对技术和安全高度关注的论坛用户中,也常有理解偏差,这或许解释了为何此类问题仍普遍存在。
4. AI编程提效攻略:程序员必备提示词工程 (Prompt engineering playbook for programmers)
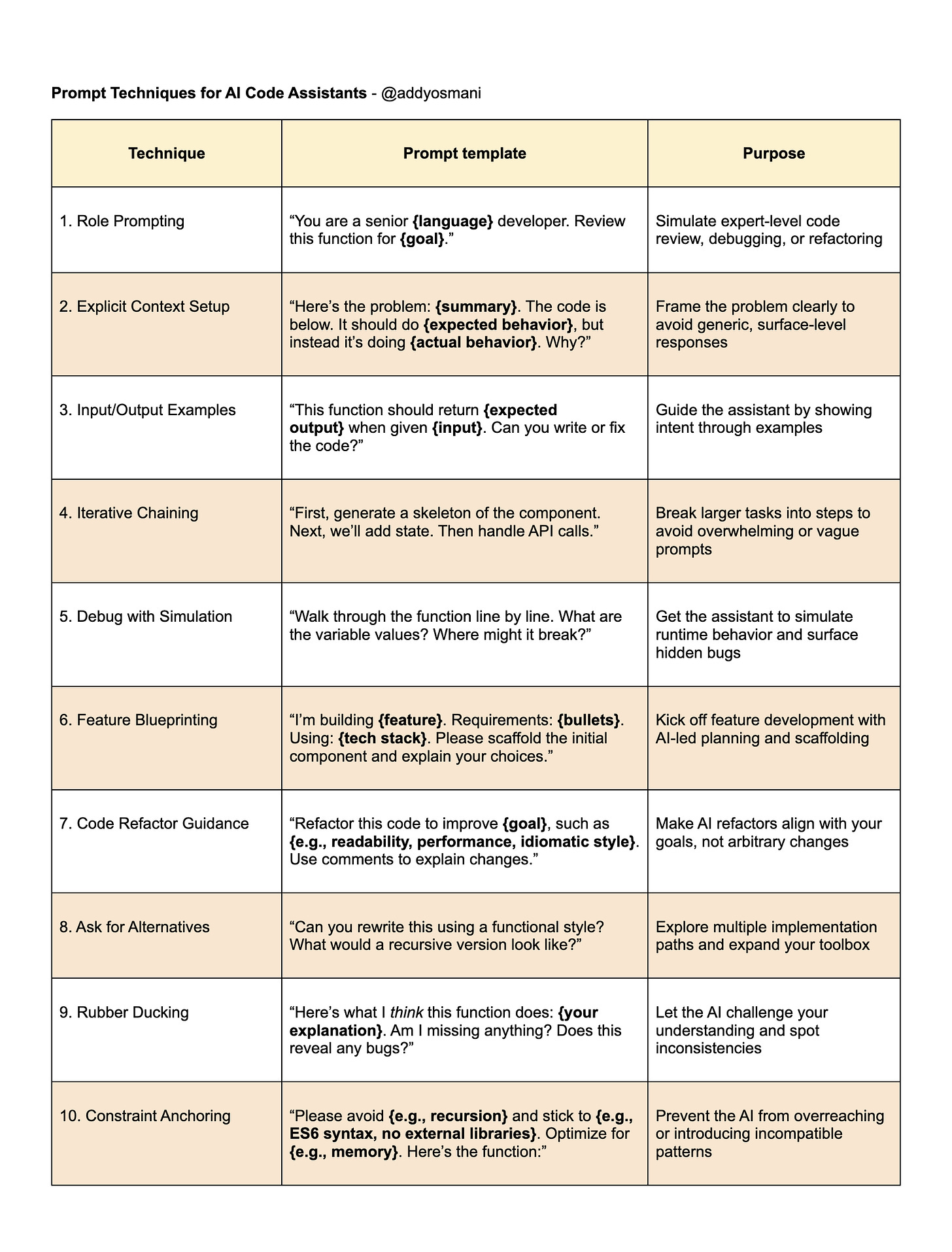

随着AI编程助手日益融入开发工作流,其输出质量与提供的“提示词”息息相关,这使得提示词工程成为程序员的必备技能。
一份最新攻略深入解析了如何提升AI协作效率。其核心在于将AI视为严谨的“结对编程”伙伴,需提供丰富的上下文、明确目标、拆解任务,并善用示例与角色扮演。通过持续迭代优化对话,能显著提高AI的理解与响应,避免模糊或冗余指令等常见误区。
该攻略指导AI在代码调试、重构优化和新功能开发等场景中的具体应用。掌握高效提示词工程,能将AI从单一工具转变为真正的智慧助手,不仅助开发者提速增效,更可在人机协作中不断学习成长。
原文链接:https://addyo.substack.com/p/the-prompt-engineering-playbook-for
论坛讨论链接:https://news.ycombinator.com/item?id=44182188
在论坛上,关于提示工程的讨论围绕其核心技术、实际效果及使用方式展开。有参与者认为,真正的提示工程方法主要包括上下文学习(通过示例)、思维链(分步思考)和结构化输出(指定格式),并提及检索增强生成(RAG)是独立概念,多数时候清晰的自然语言指令即可。
关于大型语言模型(LLM)的领域知识迁移能力,存在不同观点。有评论者强调“上下文为王”,认为LLM在不同领域间的知识迁移能力有限,需要精确“预设”才能给出恰当回答。但也有人分享自身经验,指出即使使用模糊的描述,LLM也能在特定语境下(如从“点云中的趋势线”识别“线性回归”)给出准确答案,显示出超乎预期的理解力。
对于“角色提示”的作用,讨论者意见不一。一部分人认为其作用不大,甚至是一种“自我欺骗”,强调清晰的需求、示例和迭代验证的重要性。然而,另一些人则认为“角色提示”依然微妙地存在,并非简单设定角色,而是通过使用专业术语或特定语言风格,能引导模型给出更专业或特定偏向的回答,例如医疗专业术语比日常提问更能获得有效诊断建议。
此外,有用户分享了一个有效的变体技巧:通过让LLM以为是在评估他人作品,而非用户自己的作品,能促使其给出更严苛和直接的修改建议。
5. IRS税务申报系统代码惊现GitHub,阳光报税时代来临! (IRS Direct File on GitHub)
科技界和关注生活新动态的朋友们注意啦!美国国税局(IRS)近期做了一件振奋人心的大事,为我们带来了前所未有的透明度和可能性:他们已将Direct File税务申报系统的绝大部分代码以开源软件的形式发布到了GitHub上。
作为美国政府的项目,Direct File的代码本就属于公共领域,而此次公开,更是IRS履行其在《共享IT法案》(SHARE IT Act)下义务的有力证明,甚至比原定计划提前了三周!这不仅仅是代码的公开,更是IRS建立公众信任、接受独立评估的关键一步。Direct File团队曾明确表示,开源能够确保每一位纳税人充分享受应得的税收优惠,并通过提供最准确、易用、安全的服务来赢得纳税人的信任。如今,代码的公开化,正是对这些承诺的最佳印证。
这一里程碑式的举动,为未来更多由纳税人资助的政府软件代码的开源铺平了道路,我们有理由期待更多政府服务能以透明、开放的形式呈现在公众面前,让科技的力量更好地服务于民。这无疑是政府数字化转型中一个充满希望的信号,值得所有关注技术进步和公共服务效率的人们点赞。
原文链接:https://chrisgiven.com/2025/05/direct-file-on-github/
论坛讨论链接:https://news.ycombinator.com/item?id=44182356
论坛上,关于美国国税局(IRS)“直接报税”(Direct File)项目公开源代码的讨论热烈。有评论者质疑,即便源代码公开,政府行政部门仍可能通过干预其与税收系统的互操作性或对现有税法的遵守来“扼杀”该项目。项目说明显示,“直接报税”将复杂税法转化为普通问题,用户回答后由软件转换为标准表格提交。
然而,许多讨论者对普通民众理解税法能力存疑。有人指出,税法充满“低收入家庭福利优惠”(EITC)等委婉语,普通人难以理解。虽有观点认为约30-50%的人报税情况简单可自行处理,但另有人解释,“直接报税”或通过简化问题,让软件自行判断用户资格。
讨论还聚焦税法中的模糊“边缘情况”,例如太阳能税收抵免是否涵盖屋顶维修,这类问题常需法庭判例才能明确。评论者表示,IRS客服对此帮助甚微,有偿报税软件的“审计保护”效力亦存疑。此外,IRS的专业术语(如将年度表格称为“schedule”)也令普通人困惑。对此,有解释称“schedule”也可指正式语境中的有组织列表。另有观点认为,公开代码将有利于那些有动力深入研究税法的企业和个人。
6. 塑料回收明星项目陨落危机!全球求援! (Precious Plastic is in trouble)



致力于开源塑料回收的Precious Plastic项目正面临严峻挑战,其未来走向引发全球关注。自2013年启动以来,该项目通过免费共享回收设备图纸、商业计算器等资源,集结了全球百余名志愿者。截至2023年,其影响力遍及56个国家,合作机构逾千家,去年共回收塑料140万公斤,创收超370万美元,雇佣530人,志愿者3405人,建成1175台设备,成果斐然。
然而,项目独特的开源模式,虽广惠全球,却也导致资金难以持续维持核心团队运营。目前,Precious Plastic深陷多重困境:遭遇工作室搬迁(因建筑污染和疫情);商业模式探索受限(不愿与社区竞争);面临纽约诉讼(无保险,高额律师费);社区平台开发受阻;开源社区“只取不予”心态普遍;项目设计缺陷(过度奉献,忽视自身财务可持续性);以及团队长期稳定性欠缺。
目前,Precious Plastic作为一个非营利组织,其庞大社区(千余工作空间、数千员工和志愿者、数百万美元营收)与仅3名全职员工的核心团队形成鲜明对比。组织每季度运营成本3万欧元,资金仅能支撑6个月。面对存亡抉择,Precious Plastic现向全球社区发出求助。他们呼吁社群支持与资金,以推动V5版本,彻底解决财务困境,确保项目长远发展,让这项充满科技魅力与环保情怀的事业,能持续为全球塑料污染治理贡献力量。
原文链接:https://www.preciousplastic.com//news/problems-in-precious-plastic
论坛讨论链接:https://news.ycombinator.com/item?id=44175773
论坛上,一篇关于某组织收到10万欧元捐款后全数转赠社区的讨论引发了热议。有评论者质疑该组织的问题多为“自作自受”,而非单纯的判断失误。他们认为,若想真诚地寻求额外支持,领导层应先承担责任并解决内部问题,而非承诺虚幻的“第五版”。讨论者普遍对该组织的尽职调查存疑,认为其缺乏从错误中吸取教训的迹象,甚至有人怀疑其是否为骗局。
另有用户直言,该项目更像是一群不急于收入的人所追求的“梦想”,而非在实际压力下运作的技术,堪称“生活方式慈善”。他们指出,文章虽充斥“社区”和“当地人”等词汇,但细节匮乏,处处可见疑点。例如,解释因租赁的机器车间关闭而贱卖机器,却未能解释为何不选择廉价的临时仓储。这暗示着可能遗漏了对其不利的关键信息。该用户还提及,其“开放学院”的“商业计算器”内容过于基础且自2020年起未更新,对所谓的“第五版”进展表示强烈怀疑。
然而,也有观点指出,搬运重型机械(如两千磅的铣床)并非易事,需要专业设备和高昂的搬运费用。这或许解释了该组织为何选择低价出售机器,而非自行搬迁,从而规避了巨大的成本和精力投入。
7. AI 抓取致瘫服务器,网站管理员祭出“Anubis”防御系统 (FFmpeg merges WebRTC support)


网站管理员正部署名为“Anubis”的新型防护系统,以应对AI公司大规模抓取数据导致的服务器瘫痪问题。Anubis借鉴了曾用于反垃圾邮件的“Hashcash”工作量证明(PoW)方案。其核心原理是:对普通用户而言,验证任务的计算量微乎其微,但对于海量抓取数据的AI程序,累积成本则会变得极其高昂,有效提高了恶意抓取门槛,保护网站资源可访问性。值得注意的是,Anubis需要现代JavaScript支持。
Anubis目前虽是“临时解决方案”,但其最终目标是开发更精准的“无头浏览器”指纹识别技术(如通过字体渲染),从而更准确识别合法用户,减少不必要的PoW挑战。这反映出AI的快速发展已改变网站托管的“社会契约”,促使网络安全领域不断创新,这类技术博弈令人充满好奇与期待。
原文链接:https://git.ffmpeg.org/gitweb/ffmpeg.git/commit/167e343bbe75515a80db8ee72ffa0c607c944a00
论坛讨论链接:https://news.ycombinator.com/item?id=44182186
论坛上,一位开发者对WebRTC广播的进展表示极度兴奋,指出GStreamer、OBS和FFmpeg对WHIP协议的支持,标志着视频广播拥有了适用于所有平台(移动、网络、嵌入式、广播软件等)的通用协议,这是他多年努力的重大里程碑。
其他评论者对这位开发者在WebRTC领域的工作大加赞赏,称其“非凡”并感谢他的努力。有评论者提出,WebRTC多播是否能实现像Twitch那样的规模,而无需亚马逊级别的预算。对此,开发者确认这是可行的,随着OBS合并相关PR,并利用Simulcast技术(多码率同传),成本将主要集中在带宽上。他举例说明,使用Hetzner的服务器,仅需1美元/TB的带宽费用,一台服务器就能支持数百用户观看4K视频,并承诺将致力于让这项技术普惠大众。
讨论中,有人好奇商品服务器的上传带宽极限,并估算18Gbps的上传带宽足以支持10,000至20,000名观众。有评论者探讨了P2P(点对点)流媒体的可能性,设想通过一级观众向二级观众进行分发,以应对普遍的千兆对称网络,尽管有用户指出CGNAT(运营商级NAT)可能带来挑战。
8. 观鸟神器!Merlin App助你轻松识别鸟类 (Merlin Bird ID)
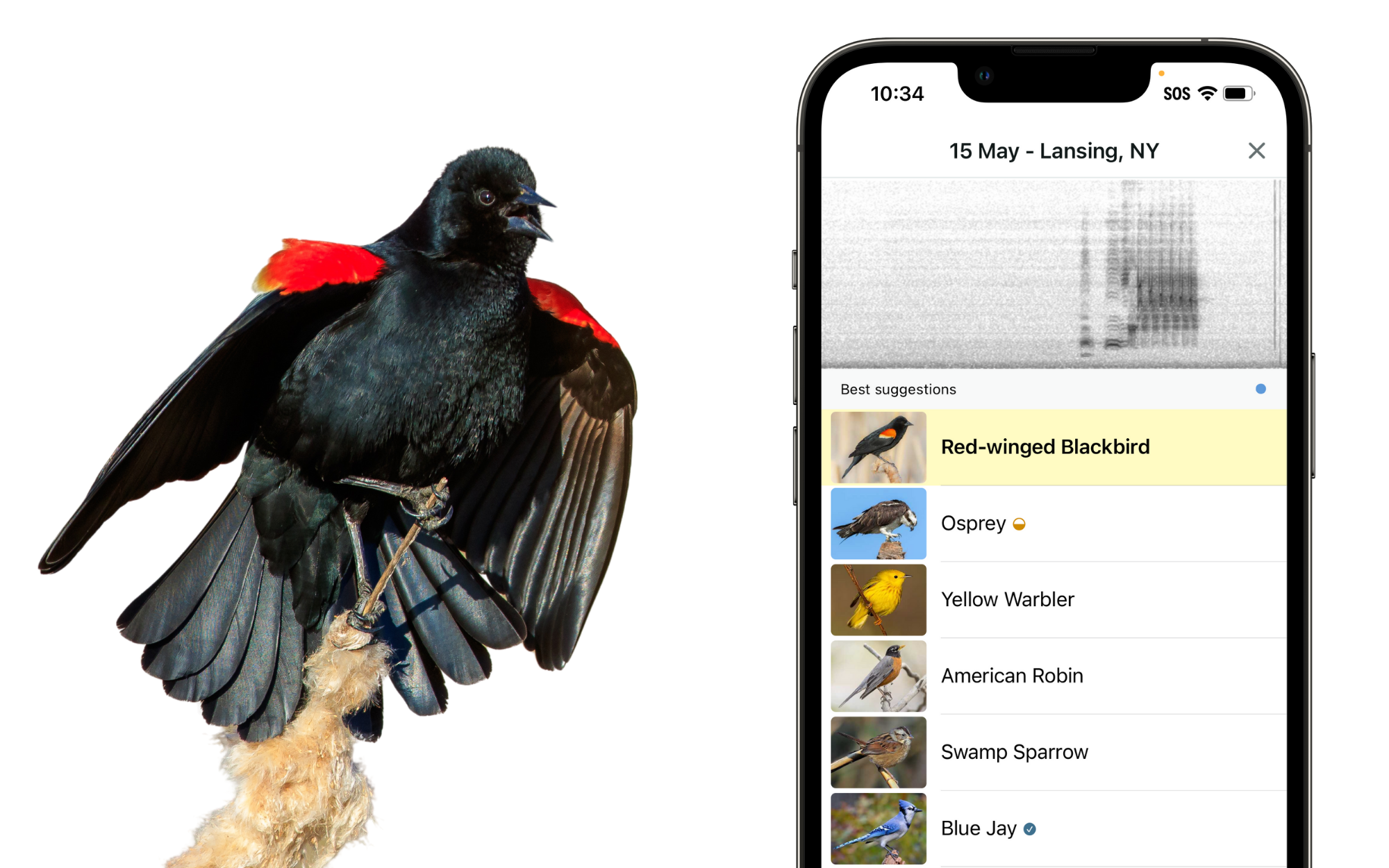
Merlin识鸟应用为科技爱好者和观鸟新手带来福音,让探索自然界的奇妙生灵变得前所未有的简单与乐趣。这款智能应用集多项创新功能于一身,旨在帮助用户轻松识别身边或照片中的鸟类。
其核心功能包括“听声辨鸟”(Sound ID)和“拍照识鸟”(Photo ID)。Sound ID能实时聆听周围鸟鸣并给出匹配建议,支持与内置鸣叫库比对;Photo ID则允许拍摄或导入照片快速识别。两项功能均支持完全离线使用,确保用户无论身处何地都能随时随地识鸟。Sound ID目前已覆盖美国、加拿大、欧洲及部分中南美洲、印度常见鸟类,未来将持续扩展物种和区域。
此外,Merlin还设有“识鸟向导”(Bird ID Wizard),通过回答三个简单问题即可获得潜在鸟种推荐,极大方便各级别观鸟爱好者。用户可创建专属的“观鸟足迹”(Life List),将每一次识别的鸟类添加到个人数字“剪贴簿”中,记录珍贵回忆。
Merlin应用依托于全球最大的公民科学观鸟数据库eBird,汇聚了数十亿条鸟类观测数据、社区贡献的图片、鸣声、专家建议及全球分布图。它为热爱自然、好奇生活的我们,打开了一扇通往鸟类世界的全新大门。
原文链接:https://merlin.allaboutbirds.org/
论坛讨论链接:https://news.ycombinator.com/item?id=44176829
该论坛的讨论主要围绕Merlin鸟类识别应用展开,用户普遍对其赞誉有加。
一位用户分享了自己使用Merlin后的积极体验,称其改变了日常作息,能识别多种鸟类及其独特叫声,甚至能区分个体。他表示唯一的改进建议是希望应用能提供保存特定鸟叫声录音和对应照片的功能,以便追踪经常光顾的个体。
另一位用户指出Merlin的“探索”和“生活清单”部分已有图片和叫声功能,但也批评了应用在添加鸟类到“生活清单”时,地点和时间默认设置不佳的问题。有评论建议,对于更专业的观鸟记录,可以使用独立的eBird应用,该应用能创建特定地点和时间的清单,并提供了灵活的计数方式。原帖作者进一步澄清,他希望的是能够隔离和存储 特定的 鸟叫声片段以及自己拍摄的 相应照片,用于追踪 单个 经常造访的鸟。
讨论中,有用户幽默地将对鸟类的着迷视为“人到四十”的标志。一位评论者赞扬Merlin是移动应用连接人与自然的典范,并指出其由康奈尔鸟类学实验室运营,拥有透明的募捐模式,有望保持免费和高质量。另有人推荐了iNaturalist,并呼吁社区支持这类公益性应用,以避免它们走向过度商业化。
9. DiffX:下一代可扩展差异格式,革新代码变更管理 (DiffX – Next-Generation Extensible Diff Format)
热爱科技的你,一定熟悉软件开发中的diff文件。它记录代码变动,是开发者日常不可或缺的工具。然而,现有主流的“统一Diff格式”在标准化编码、元数据、二进制差异及多提交记录方面存在局限,给现代开发工具带来诸多挑战。
好消息是,“DiffX”(可扩展Diff格式)应运而生!它在完全向后兼容统一Diff的基础上,创新引入结构化可扩展元数据标准,并支持二进制文件差异、单文件多提交信息及文本编码,极大增强了Diff文件的能力。
DiffX秉持开放原则,不强制升级、不破坏现有工作流。它通过标准化解析规则,赋能开发工具更智能地理解和处理代码变更,显著提升效率与协作。知名代码审查工具Review Board已率先采用。
原文链接:https://diffx.org/
论坛讨论链接:https://news.ycombinator.com/item?id=44176737
论坛上,一位评论者对新格式的高度层级化设计表示不满,尤其质疑“meta”块依赖“点”数指示深度,建议使用不同名称来提高可读性并降低错误,并指出不同层级元数据的字段应有区别。该评论者还质疑JSON与键值对两种数据格式并存,主张统一格式以简化解析和工具集成。
回复者解释称,早期设计曾尝试其他命名,但最终选择当前基于#<section_level><section_type>的结构,层级通过“点”数区分,旨在简化解析。关于格式,回复者澄清键值对用于简单头部信息,JSON用于灵活元数据块。JSON的选择经过广泛讨论与实验,且元数据块头部可指定序列化格式,以避免未来受限。
此外,针对兼容性问题,回复者指出列表末尾逗号不被支持,以兼顾无JSON5解析器用户。关于差异分割,回复者表示传统工具可忽略额外数据实现分割;但若分割成新的DiffX文件,过程则更复杂,需重新添加前导信息。