1. 3D打印无源“声棱镜”:白噪音绽放声学彩虹 (3D-printed device splits white noise into an acoustic rainbow without power)


发表于《科学进展》的一项激动人心研究揭示,丹麦技术大学与马德里理工大学的科研人员联手,成功开发出“声学彩虹发射器”(ARE)。该设备创新性地将单一宽带白噪声源发出的声音,像棱镜分光般根据不同频率精准散射至不同方向,从而实现“声学彩虹”。此举突破了现有声学系统在自由空间宽频声波操控的局限,巧妙地模拟了生物耳道利用被动结构塑造声波的能力。研究团队运用计算形态发生、拓扑优化及3D打印等前沿技术,获得前所未有的设计自由度,精准操控声波。
原文链接:https://phys.org/news/2025-06-3d-device-white-noise-acoustic.html
论坛讨论链接:https://news.ycombinator.com/item?id=44282953
社区上的一场讨论围绕声学反射现象展开。一位用户分享了1980年代末的经历,发现建筑物上垂直波纹的表面在雷暴时能将雷声反射成快速下降的音调,这类似于声学衍射光栅,不同频率向不同方向反射。
有用户对此现象深感兴趣,并提出疑问:是否能通过改变波纹排列来编码预设的声音反射?有人甚至问这是否意味着能将“森林树叶沙沙声”编码进混凝土。讨论者澄清,这更像是利用脉冲响应(IR)技术,通过短促声音制造特定反射声,而非模拟自然长音;均匀排列的圆形杆在风中可产生类似风琴的持续声音。
随后,讨论转向了更复杂的物理学应用。有用户将声学波纹联想至光子学中无源解复用器的有机形状,并分享了一篇相关论文。论文中展示的“疯狂形状”引发了关于其设计方式的讨论:是可以通过分析方法推导,还是依赖搜索算法?有评论者认为,波方程可能存在对称和结构的解,只是目前工具和知识不足。最后,有人指出,论文中寻找这些形状的方法并非严格意义上的“机器学习”,而更像是通过模拟进行的优化。
2. AI文档撰写:让机器读懂知识,精准作答 (Writing documentation for AI: best practices)
![]()

近年来,检索增强生成(RAG)系统如Kapa正革新我们获取信息的方式,它们将人工智能与现有知识库深度融合,为用户提供精准答案。这项技术的核心在于文档质量:优质文档不仅能有效服务人类读者,更能显著提升AI系统的响应能力,形成内容质量的良性循环。
文档质量的重要性从未如此凸显。当AI系统依赖同一内容回答用户问题时,糟糕的文档不仅会令人类用户感到沮丧,更会直接降低AI回答的准确性,导致“劣质内容产出劣质答案”的恶性循环。AI系统处理文档的方式揭示了其对内容质量的严苛要求:它们通过检索器在向量数据库中寻找相关“知识块”,再由大型语言模型(LLM)生成答案。
然而,AI在理解文档时面临独特挑战:它们以离散的“知识块”而非连续叙事来处理信息,依赖内容匹配而非逻辑结构,且无法推断未明确说明的信息或保留隐含关联。因此,为AI优化的文档应具备明确性、自包容性和上下文完整性,确保每个知识块都能独立存在并清晰关联。这种精细化的内容组织能显著提升检索准确性,让AI更有信心地回答问题,最终极大改善“AI问答”界面的用户体验。
原文链接:https://docs.kapa.ai/improving/writing-best-practices
论坛讨论链接:https://news.ycombinator.com/item?id=44311217
社区的讨论围绕人工智能对文档和代码质量的影响展开。发帖人指出,为AI优化文档,实则就是回归到良好文档的本质:清晰的上下文、层级结构、独立章节和精确的错误信息,这颇具讽刺意味。有评论者将其与搜索引擎优化(SEO)类比,认为好的SEO实践(如结构、HTML使用、加载速度和可访问性)同样是良好的通用网络实践。
然而,也有人反驳说,实际操作中许多SEO内容沦为垃圾,仅为迎合算法,而非追求实际意义或有用性。
讨论转向代码编写,有人提到AI促使开发者更好地阐明问题,并将其分解为子问题以供大型语言模型(LLM)解决,这本质上是重新发现了标准软件工程实践的价值。有开发者表示,AI改变了他们的代码结构,让代码编写过程更加自然顺畅。还有人发现详细的变量命名有助于AI提供有用的自动补全。
此外,讨论者普遍认为AI是评估API和代码清晰度的有效工具。正如一条评论所言,“如果AI代理都无法理解你的API如何工作,那么你的用户也一样。” AI被视为代码审查的利器,尤其是在缺乏强有力同行意见时。甚至有人建议,将AI认知复杂性冒烟测试作为API/模式设计的基本组成部分,认为即使LLM“愚蠢”,“愚蠢即服务”也确实有用。
3. A算法:智能寻路,最短路径的魔法 (Introduction to the A Algorithm (2014))

哇!科技魅力无限!图搜索算法,特别是神奇的A算法,正引领我们探索地图上的最短路径奥秘。想象一下,无论是游戏角色智能导航,还是现实世界路线规划,A都能大显身手!它通过分析抽象的“节点”和“边”构成的图结构,高效找出最优路径。除了最短路径,这些算法还能应用于距离图、流场寻路、地图分析等诸多领域,为游戏开发、AI等注入无限可能。虽然A*不关心地图的物理细节,只专注于图结构,但正是这种抽象能力,让它强大且灵活。
原文链接:https://www.redblobgames.com/pathfinding/a-star/introduction.html
论坛讨论链接:https://news.ycombinator.com/item?id=44296523
社区中,关于图遍历算法的讨论指出,A*、广度优先搜索(BFS)和迪杰斯特拉(Dijkstra)算法本质上是同一种算法,其核心区别在于优先级队列的策略:BFS基于发现顺序,迪杰斯特拉基于路径累计距离,A则额外考虑目标估算距离。一位讨论者推断,A的“可接受启发式”必须低估真实值,因迪杰斯特拉可视作A*估算为零的特例。
另一位讨论者提出,所有图遍历皆可用“未知”、“已知未访问”和“已访问”节点集合表示,算法差异体现在“已知未访问”集合的数据结构上:如DFS用栈,BFS用队列(后经纠正),迪杰斯特拉用基于边权重的优先级队列,A*用带启发函数的优先级队列。
讨论强调,A的启发函数必须“可接受”,即永不高估真实值,以保证找到最短路径;即便启发函数不可接受,A仍能找到路径,但非最短。有参与者建议,可借用地图上直线距离总低估实际距离的例子来理解可接受启发式。更有趣的观点认为,A*本质上是迪杰斯特拉算法在经过启发式调整边权后的图上运行。
4. Workout.cool:健身开源平台浴火重生,你的智能私教新选择! (Show HN: Workout.cool – Open-source fitness coaching platform)
![]()
健身科技爱好者们,福音来了!曾风靡一时的开源健身平台workout.lol不幸停摆,但其原核心开发者毅然重启,并推出全新力作workout.cool。这不仅是简单的复活,更是全面革新!作为一款功能强大的健身指导平台,它能助你定制训练计划、追踪进度,更有海量附带详细视频教程的动作库。项目采用Next.js、PostgreSQL等前沿技术,遵循FSD原则,秉持“源于社区,服务社区”的理念,旨在为全球健身爱好者打造一个可靠、现代、持续维护的开源健身工具。
原文链接:https://github.com/Snouzy/workout-cool
论坛讨论链接:https://news.ycombinator.com/item?id=44309320
社区上的一场讨论围绕健身应用“workout.lol”及其继任者“workout.cool”展开。原作者惊喜地发现,在将其出售给一位已放弃维护的买家后,该项目重新焕发生机,并赞扬了新维护者在用户界面上的改进。新维护者Vincenius对此表示兴奋,解释了项目一度停滞后,自己秉持原作者的开放精神重建项目的初衷,并邀请原作者回归。
讨论中,有用户向社区管理员建议增设一个名为“collab”的板块,用于“错失的技术连接”,希望以此重新连接旧项目(如废弃的内部工具、代码库)或寻找合作者。对此,有用户认为其有趣,类似于旧项目版的“tell-hn”,但对其具体实用性存疑;另有通过研究废弃项目自学的开发者表示支持,并希望能找到导师。
此外,一位正在开发自动化日历调度API的用户发现“workout.cool”项目完美契合其需求,该API旨在围绕目标规划生活和膳食。新维护者对此表示欢迎,并强调“workout.cool”正是为此类开放、易于集成的工作流而设计。讨论末尾,有评论猜测原买家收购项目可能是为了阻止免费替代品的流行。
5. 同态加密赋能CRDTs,无缝隐私协作新时代 (Homomorphically Encrypting CRDTs)


在数字化协作日益普及的当下,本地优先(local-first)软件凭借CRDT(无冲突复制数据类型)技术,让远距离协同编辑文档变得高效便捷。然而,当文档内容高度机密,不愿让应用开发者知晓时,隐私保护便成为核心挑战。
端到端加密(E2EE)曾是主要解决方案,用户通过共享密钥加密传输,确保信息安全,Excalidraw等应用已成功实践。但E2EE也带来新问题:当用户异步工作时,加密数据导致同步服务器无法直接合并更改,协作效率受限,隐私与便利陷入两难。
令人振奋的是,一项前沿技术——同态加密(Homomorphic Encryption, HE)——正带来突破!它允许计算机在不解密数据的情况下,直接对其进行运算。这意味着,未来的同步服务器将能直接处理同态加密的CRDT数据,实现无感合并,完美平衡内容隐私与协作效率。
这项创新无疑为本地优先软件开启了无限可能,预示着一个既能保障数据绝对隐私,又能享受无缝、异步协作体验的全新时代。
原文链接:https://jakelazaroff.com/words/homomorphically-encrypted-crdts/
论坛讨论链接:https://news.ycombinator.com/item?id=44309520
社区讨论围绕全同态加密(FHE)和无冲突复制数据类型(CRDTs)的性能与发展展开。一位讨论者指出,FHE虽然目前效率低下,但自2009年首次发现以来已取得巨大进步,密钥大小从最初的TB/PB级别大幅缩减至30MB,引导操作时间也从数千小时缩短至不到0.1秒,展望其未来实用性。另一位讨论者则提出了在学生设备上使用FHE加密的WASM或JS代码进行作业评分时,关于信任和安全性的疑问。
关于CRDTs,有评论指出其早期版本如WOOT并不实用,但现代CRDT数据库在性能上已与LSM树相近,通过归并排序算法优化了元数据开销。然而,也有人质疑CRDTs固有的高成本,认为即使是优化后的算法也因设计而效率不高,与FHE结合更具挑战。对此,一位知名研究者反驳称CRDTs并非天生缓慢,并指出现有优化仍处于早期阶段,仍有巨大提升空间。他作为一篇被引用文章的作者,补充说明该文章内容已过时,CRDTs的性能通过新方法进一步提升,例如Automerge 3测试版已显著提速,优秀的CRDT库应能处理每秒数百万次更改。社区成员对此表示期待,希望看到更多关于CRDTs的最新文章。讨论也提及FHE和CRDTs结合时会增加开销,且这种开销通常是每项操作的倍数级。
6. Scrappy:你的专属“家常”小应用 (Scrappy – Make little apps for you and your friends)

现有软件多为大众通用或企业定制,缺乏为个人及亲友量身定制的“家常软件”。开发者John和Pontus为此推出研究原型Scrappy。
Scrappy赋能用户轻松制作个性化“Scrappy应用”(Scrapps),它们不求华丽,但能精准满足特定需求。例如,为孩子定制算术App,为活动创建共享计数器,或15分钟搭建会议成本计时器等。Scrappy描绘了软件作为创意、个人化表达工具的未来图景,虽是原型,但潜力巨大。它预示着软件将从大众化走向个性定制,为热爱科技、好奇生活的我们,开启创造性、贴心数字体验新篇章。
原文链接:https://pontus.granstrom.me/scrappy/
论坛讨论链接:https://news.ycombinator.com/item?id=44306859
社区中一场关于轻量级应用开发工具的讨论围绕Scrappy展开。一位讨论者指出,CardStock和Decker是Scrappy的替代品。CardStock开源且支持本地运行,与Scrappy目标相似;而Decker同样开源,提供了处理表格数据、查询语言、网格组件及可重用模块等Scrappy路线图上提及的功能。另一位讨论者对Decker的桌面应用特性表示赞赏,称其正是自己一直在寻找的工具。
然而,有评论者对Scrappy作为托管SaaS解决方案的模式表示担忧。他们认为,对于个人长期项目而言,过度依赖第三方SaaS存在风险,因为创始人可能会转向其他项目,导致解决方案不可持续。该评论者偏好能长期使用、学习曲线低且易于构建图形用户界面的工具,例如基础的HTML/CSS/JS,甚至简单的PHP后端。他们指出,就像MySpace用户能学习CSS一样,代码不需完全抽象,只需易用且符合用户需求。他们举例AutoHotKey脚本能运行十多年无需维护,而SaaS则无法保证这种持久性。最后,有讨论者建议,类似TiddlyWiki那种将整个Web应用封装在单个HTML文件中、可自复制并选择性连接后端的方式,可能是更可靠的轻量级应用开发方案。
7. Poline:极线绘彩,调色板的艺术奥秘 (Poline – An enigmatic color palette generator using polar coordinates)
近日,一款名为“Poline”(发音/ˈpɔːlaɪn/)的TypeScript微型库问世,为数字设计注入新鲜活力。其名“极线”寓意深远,象征着通过在“锚点”间绘制线条来创造丰富多彩的调色板,完美诠释了其核心功能与设计理念。
Poline的核心在于简化色彩生成过程,让复杂的美学创作变得触手可及。它引入了“锚点”(anchors)作为线条的基础点,而“点”(points)的数量则直接决定了每对锚点间生成的颜色密度——点越多,色彩过渡就越细腻丰富,为创作者提供了无限可能性。同时,“位置函数”(position functions)精妙地控制着这些点的精确位置,从而实现对色彩渐变和分布的精准掌控。
这款微型库的出现,无疑是前端开发者和设计师们的福音。它提供了一种新颖高效的方式来生成定制化、艺术化的调色板,极大地降低了色彩探索的门槛,让那些对视觉美学充满好奇的朋友也能轻松玩转色彩。
原文链接:https://meodai.github.io/poline/
论坛讨论链接:https://news.ycombinator.com/item?id=44279569
社区上,一位讨论者分享了自己构建一个神秘主题网站的乐趣,坦言其色彩选择纯粹凭直觉,并非基于科学或理论。
对此,另一位回复者指出,关于色彩和谐的文献并非完全空白,他提到了松田对色彩选择原则的研究,以及库尼关于色彩空间的著作。他还强调,尽管色相对立(互补色原理)易于研究且达芬奇早已记录,但相关研究仍是空白。该回复者进一步探讨了色彩和谐的神秘维度,指出从牛顿到伊顿、歌德、康定斯基等人都曾相信色彩的精神层面。然而,他个人认为,后者的理论对艺术家和设计师有害,因其往往前后矛盾、模糊且存在谬误。
原讨论者随后澄清,自己提及的“缺乏科学依据”是指其设计过程完全是凭直觉判断“看起来不错”,并未尝试应用任何色彩理论,并感谢了对方提供的丰富参考资料。
8. iPhone 8逆袭:太阳能驱动,变身离网OCR服务器 (My iPhone 8 Refuses to Die: Now It’s a Solar-Powered Vision OCR Server)
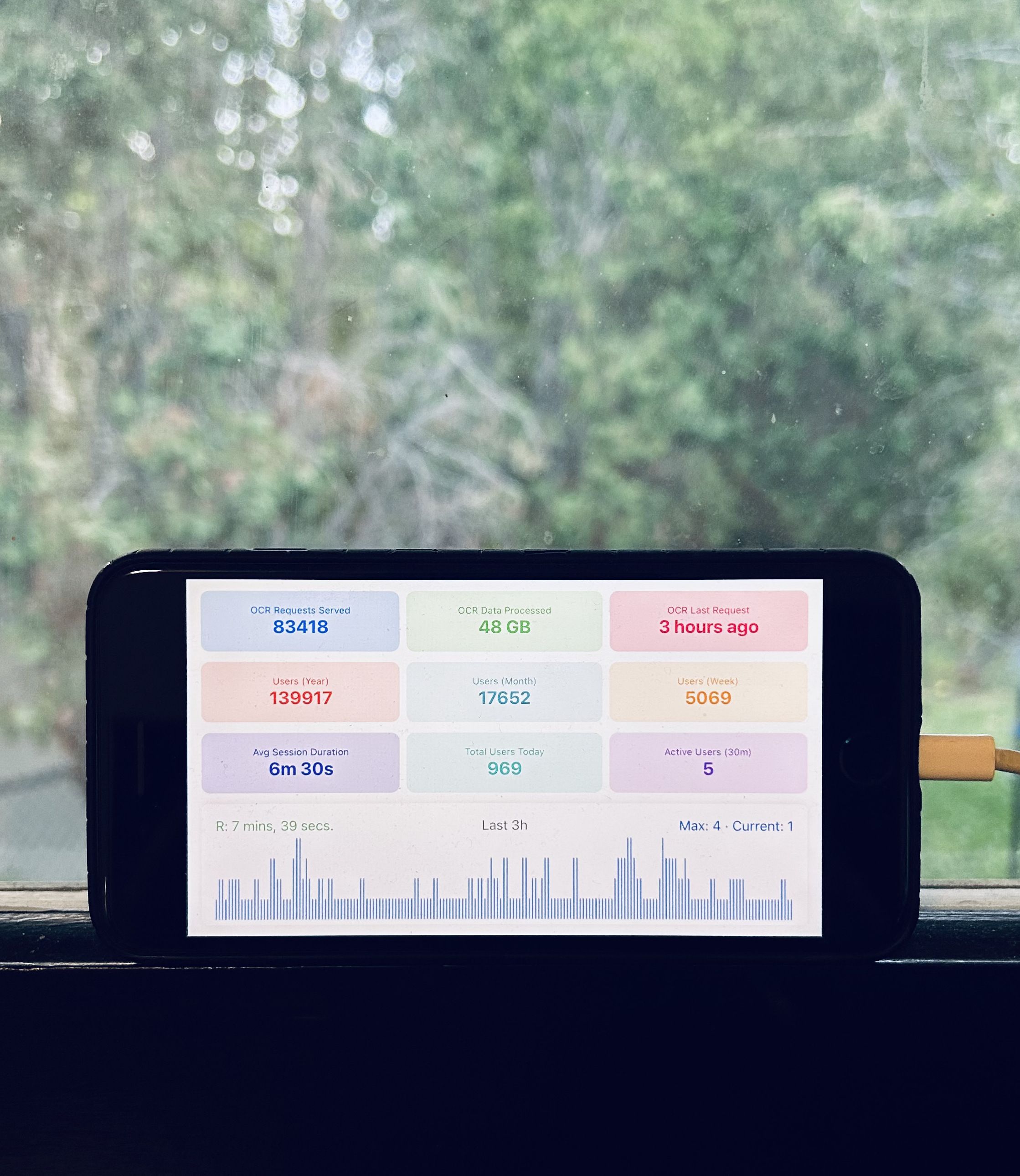
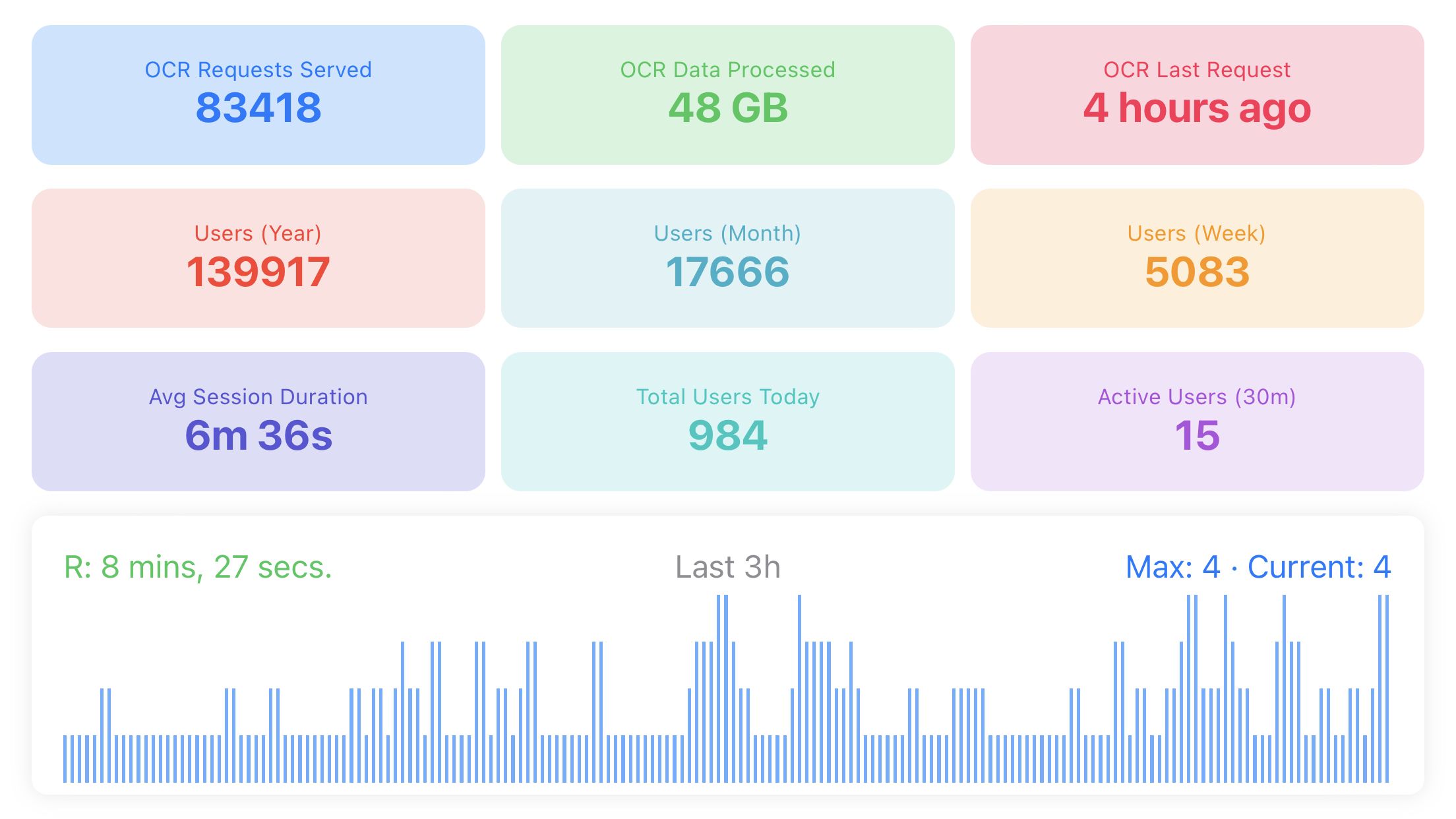
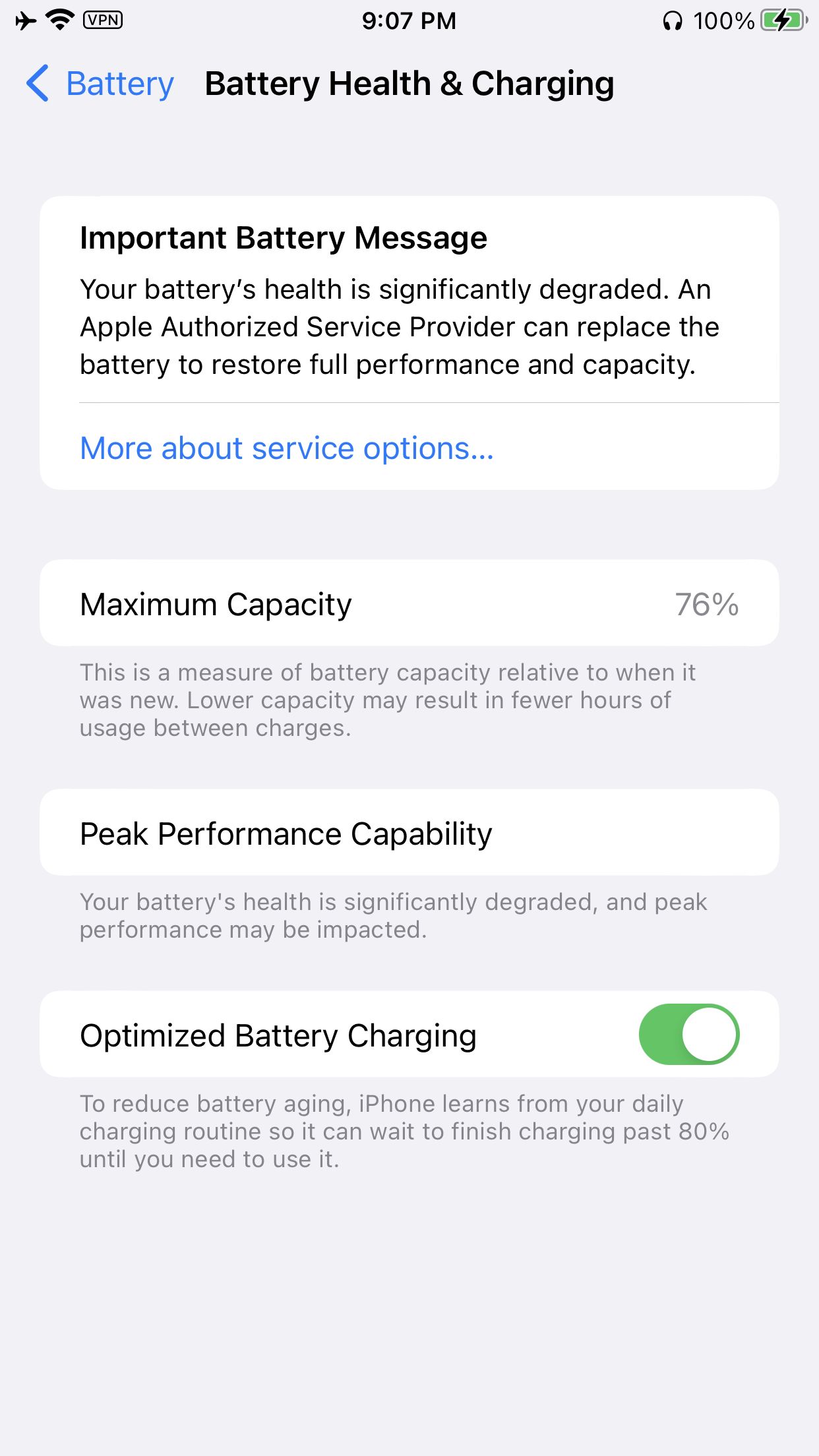
一位科技爱好者将闲置的iPhone 8巧手改造,使其变身为一台太阳能供电的离网OCR服务器。过去一年,这台“再生”设备已成功处理83,418个OCR请求和48GB图像数据,全部依托Apple Vision框架和清洁能源。此举不仅每年节省84-120加元电费,更证明了旧硬件在创新应用下的惊人可靠性与潜力。这不仅是一项充满乐趣的科技实验,更是对环保节能、独立计算生活方式的积极探索,展现了科技与日常的奇妙融合。
原文链接:https://terminalbytes.com/iphone-8-solar-powered-vision-ocr-server/
论坛讨论链接:https://news.ycombinator.com/item?id=44310944
社区的一场讨论围绕苹果每年99美元的开发者费用及其对用户设备所有权的影响展开。一位用户抱怨,尽管每年能节省约84-120加元,但苹果的99美元开发者年费(用于在自己的手机上运行自己的应用超过一周)几乎抵消了这些节省。他认为苹果“允许”用户使用设备的说法,使得用户在支付全款后仍感觉只是向苹果借用设备,表达了对苹果又爱又恨的复杂情感。
针对此费用,有评论者认为其荒谬,质疑苹果是否真的需要99美元来维护基础设施和服务器。另有观点指出,公司的定价并非由成本决定,而是基于最大化利润,并提出99美元的费用可能旨在过滤低质量应用、防止垃圾邮件、减轻审批人员工作量以及创造收入。他们认为价格不存在“合理与否”,而是用户选择是否支付。
然而,也有人反驳说,在自由市场中,价格应由成本决定,但像手机行业这样的寡头垄断者会滥用系统挤压消费者。另一些人则坚持在自由市场中,价格由消费者“愿意支付”的意愿决定,而非成本。讨论中还提及公司通常会尽可能收取高价,以及垄断地位对定价的影响。整体而言,社区成员对苹果的定价策略和其在设备所有权上的立场持有截然不同的看法。
9. MiniMax-M1:开源混合注意力推理巨擘,AI长文本智能新标杆 (MiniMax-M1 open-weight, large-scale hybrid-attention reasoning model)

科技界传来振奋人心的消息!MiniMax公司近日发布了MiniMax-M1模型,这是全球首个开源、大规模的混合注意力推理模型,为人工智能领域注入了强大新活力。
MiniMax-M1基于MiniMax-Text-01开发,巧妙融合了混合专家(MoE)架构与创新的“闪电注意力”机制。它拥有4560亿总参数,每词元激活459亿参数,原生支持100万词元上下文长度,是DeepSeek R1的8倍,能轻松驾驭超长文本。其闪电注意力机制大幅提升计算效率,例如生成10万词元内容时,浮点运算次数仅为DeepSeek R1的四分之一,非常适合需深入思考和处理海量输入的复杂任务。
M1通过大规模强化学习训练,涵盖数学推理到软件工程等多元问题,并引入CISPO新算法以优化效率。模型已推出4万和8万两种“思考预算”版本。在多项标准基准测试中,MiniMax-M1表现出色,尤其在复杂软件工程、工具使用及长上下文任务上,超越了DeepSeek-R1和Qwen3-235B等顶尖开源模型。
原文链接:https://github.com/MiniMax-AI/MiniMax-M1
论坛讨论链接:https://news.ycombinator.com/item?id=44307290
社区内,MiniMax近期模型发布引发讨论。有用户指出,MiniMax正处于“发布周”,已推出M1大模型和海螺2。该公司此前主要以LLM和视频模型闻名,但其音频TTS技术也在某些排行榜表现突出。
针对M1模型性能,有讨论者推荐其技术报告,强调其“闪电注意力”和GRPO变体(CISPO)虽未达开源模型顶尖,但仍具重要价值。
讨论还涉及M1硬件成本:全精度运行需8块H200显卡(约25万美元),但有用户提出,通过Q4/Q8量化,模型可在低于1万美元设备甚至Mac Studio上运行。
关于量化对模型性能影响,社区看法不一:有用户认为Q8几乎无损,Q4影响不大;但也有经验者表示,重度量化模型与预量化模型相比,性能仍有明显差距。另有评论提醒,基准测试结果不完全代表实际使用场景,因大语言模型基准测试本身极具挑战性。
10. 大模型:解锁代码移植与重构的“不可能” (The unreasonable effectiveness of fuzzing for porting programs)

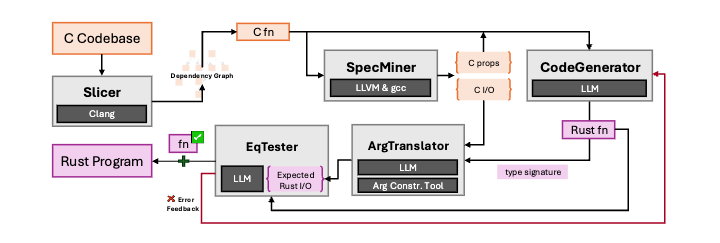
大型语言模型(LLMs)正日益成为代码生成主力,预示着代码生产将从以人为本转向以机器为本,深刻重塑软件开发与维护。
例如,LLMs已能通过编写模糊测试并按拓扑顺序构建端口,高效实现C到Rust的代码移植。这仅是能力一隅。LLMs的强大能力,让过去看似不可能的“激进更新”成为现实。LLMs能自动处理API兼容性问题,将我们从繁琐细节中解放。它们还能协助彻底重构API,甚至通过LLM提示实现下游用户代码自动化迁移,使大规模内部重构不再是难题。
过去,出于客户影响和投入产出比考量,高级工程师常规避此类颠覆性改动。但若仅需“找到合适提示词,交由LLM完成”,决策模式将根本性转变。鉴于TensorFlow等大型项目曾面临的巨额技术债务和“职业晋升综合症”导致的代码膨胀,维护大型库的艰辛不言而喻。LLMs介入有望摆脱这些历史包袱,促使代码库更清洁、高效、适应性强。
原文链接:https://rjp.io/blog/2025-06-17-unreasonable-effectiveness-of-fuzzing
论坛讨论链接:https://news.ycombinator.com/item?id=44311241
社区讨论围绕代码中“微妙逻辑路径”的发现与测试展开。一位参与者提出,多数代码不含复杂逻辑,大量测试输入足以验证其正确性。但此观点立即遭到反驳,指出这可能过于乐观,许多错误能通过简单测试,尤其在处理边缘情况时,代码中的微妙错误难以发现,并以Timsort算法的著名bug为例。讨论者们还探讨了模糊测试(fuzzing)在此类复杂场景中的局限性,认为其可能无法发现需要特定巨量输入或特殊配置才能触发的bug。
讨论随后转向大型语言模型(LLMs)在代码生成中的表现。有观点认为,LLMs通常能生成正确的代码,即使有错误也多是易于修复的“显而易见的愚蠢错误”。然而,如果LLMs引入了难以察觉的微妙bug,那将更具挑战性。对此,一位经验丰富的开发者表示强烈质疑,认为在多数编码任务中,LLM远未达到“几乎正确”的水平。他指出,要让LLM生成可用代码,往往需要耗费大量精力进行冗长提示,其付出甚至超过手动编写。更甚者,LLM引入的错误常是隐蔽且难以调试的,例如遗漏关键逻辑或移除安全检查,这迫使开发者必须逐行细致审查代码,大大增加了调试成本。